Medical & Biological Engineering & Computing ( IF 2.6 ) Pub Date : 2020-08-25 , DOI: 10.1007/s11517-020-02245-2 Nasir Mahmood 1, 2 , Saman Shahid 3 , Taimur Bakhshi 3 , Sehar Riaz 4 , Hafiz Ghufran 4 , Muhammad Yaqoob 5
|
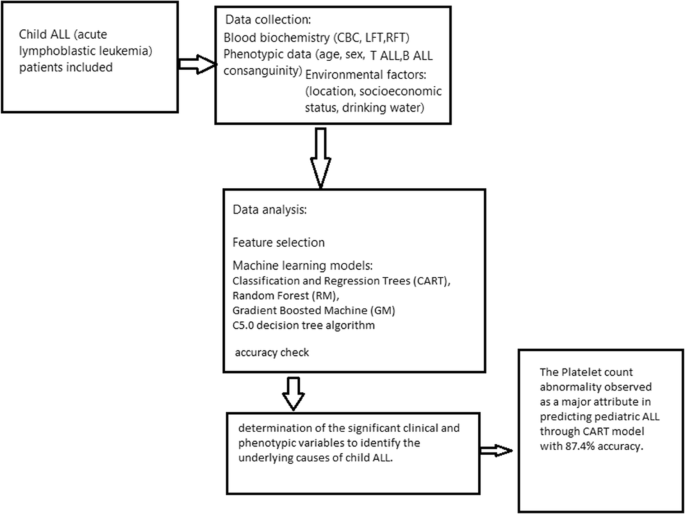
Pediatric acute lymphoblastic leukemia (ALL) through machine learning (ML) technique was analyzed to determine the significance of clinical and phenotypic variables as well as environmental conditions that can identify the underlying causes of child ALL. Fifty pediatric patients (n = 50) included who were diagnosed with acute lymphoblastic leukemia (ALL) according to the inclusion and exclusion criteria. Clinical variables comprised of the blood biochemistry (CBC, LFTs, RFTs) results, and distribution of type of ALL, i.e., T ALL or B ALL. Phenotypic data included the age, sex of the child, and consanguinity, while environmental factors included the habitat, socioeconomic status, and access to filtered drinking water. Fifteen different features/attributes were collected for each case individually. To retrieve most useful discriminating attributes, four different supervised ML algorithms were used including classification and regression trees (CART), random forest (RM), gradient boosted machine (GM), and C5.0 decision tree algorithm. To determine the accuracy of the derived CART algorithm on future data, a ten-fold cross validation was performed on the present data set. The ALL was common in children of age below 5 years in male patients whole belonged to middle class family of rural areas. (B-ALL) was most frequent as compared with T-ALL. The consanguinity was present in 54% of cases. Low levels of platelets and hemoglobin and high levels of white blood cells were reported in child ALL patients. CART provided the best and complete fit for the entire data set yielding a 99.83% model fit accuracy, and a misclassification of 0.17% on the entire sample space, while C5.0 reported 98.6%, random forest 94.44%, and gradient boosted machine resulted in 95.61% fitting. The variable importance of each primary discriminating attribute is platelet 43%, hemoglobin 24%, white blood cells 4%, and sex of the child 4%. An overall accuracy of 87.4% was recorded for the classifier. Platelet count abnormality can be considered as a major factor in predicting pediatric ALL. The machine learning algorithms can be applied efficiently to provide details for the prognosis for better treatment outcome.
中文翻译:
通过机器学习 (ML) 方法识别小儿急性淋巴细胞白血病 (ALL) 的重大风险。
通过机器学习 (ML) 技术对小儿急性淋巴细胞白血病 (ALL) 进行分析,以确定临床和表型变量以及可识别儿童 ALL 根本原因的环境条件的重要性。50 名儿科患者 ( n = 50) 包括根据纳入和排除标准诊断为急性淋巴细胞白血病 (ALL) 的患者。临床变量包括血液生化(CBC、LFT、RFT)结果和 ALL 类型的分布,即 T ALL 或 B ALL。表型数据包括孩子的年龄、性别和血缘关系,而环境因素包括栖息地、社会经济地位和过滤饮用水的获取。为每个案例分别收集了 15 个不同的特征/属性。为了检索最有用的判别属性,使用了四种不同的监督 ML 算法,包括分类和回归树 (CART)、随机森林 (RM)、梯度提升机 (GM) 和 C5.0 决策树算法。为了确定派生的 CART 算法对未来数据的准确性,对当前数据集进行了十倍交叉验证。ALL多见于5岁以下儿童,男性患者全部属于农村中产阶级家庭。(B-ALL) 与 T-ALL 相比最常见。54% 的病例存在血缘关系。据报道,儿童 ALL 患者的血小板和血红蛋白水平低,白细胞水平高。CART 为整个数据集提供了最佳和完全拟合,模型拟合准确率为 99.83%,整个样本空间的错误分类率为 0.17%,而 C5.0 报告为 98.6%,随机森林为 94.44%,梯度提升机器结果为在 95.61% 拟合。每个主要区分属性的可变重要性是血小板 43%、血红蛋白 24%、白细胞 4% 和儿童性别 4%。总体准确率为 87。分类器记录了 4%。血小板计数异常可被认为是预测儿科 ALL 的主要因素。可以有效地应用机器学习算法来为更好的治疗结果的预后提供详细信息。










































 京公网安备 11010802027423号
京公网安备 11010802027423号