当前位置:
X-MOL 学术
›
Comput. Animat. Virtual Worlds
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Deep supervised multimodal semantic autoencoder for cross‐modal retrieval
Computer Animation and Virtual Worlds ( IF 0.9 ) Pub Date : 2020-07-01 , DOI: 10.1002/cav.1962 Yu Tian 1 , Wenjing Yang 1 , Qingsong Liu 2 , Qiong Yang 1
Computer Animation and Virtual Worlds ( IF 0.9 ) Pub Date : 2020-07-01 , DOI: 10.1002/cav.1962 Yu Tian 1 , Wenjing Yang 1 , Qingsong Liu 2 , Qiong Yang 1
Affiliation
|
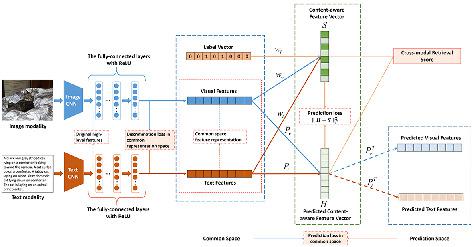
Cross‐modal retrieval aims to do flexible retrieval among different modals, whose main issue is how to measure the semantic similarities among multimodal data. Though many existing methods have been proposed to enable cross‐modal retrieval, they rarely consider the preservation of content information among multimodal data. In this paper, we present a three‐stage cross‐modal retrieval method, named MMCA‐CMR. To reduce the discrepancy among multimodal data, we first attempt to embed multimodal data into a common representation space. We then combine the feature vectors with the content information into the semantic‐aware feature vectors. We finally obtain the feature‐aware and content‐aware projections via multimodal semantic autoencoders. With semantic deep autoencoders, MMCA‐CMR promotes a more reliable cross‐modal retrieval by learning feature vectors from different modalities and content information simultaneously. Extensive experiments demonstrate that the proposed method is valid in cross‐modal retrieval, which significantly outperforms state‐of‐the‐art on four widely‐used benchmark datasets.
中文翻译:

用于跨模态检索的深度监督多模态语义自动编码器
跨模态检索旨在在不同模态之间进行灵活的检索,其主要问题是如何衡量多模态数据之间的语义相似性。尽管已经提出了许多现有方法来实现跨模态检索,但它们很少考虑在多模态数据之间保留内容信息。在本文中,我们提出了一种名为 MMCA-CMR 的三阶段跨模态检索方法。为了减少多模态数据之间的差异,我们首先尝试将多模态数据嵌入到一个公共表示空间中。然后我们将特征向量与内容信息组合成语义感知特征向量。我们最终通过多模态语义自动编码器获得了特征感知和内容感知的投影。使用语义深度自动编码器,MMCA-CMR 通过同时学习来自不同模态和内容信息的特征向量,促进了更可靠的跨模态检索。大量实验表明,所提出的方法在跨模态检索中是有效的,在四个广泛使用的基准数据集上显着优于最先进的方法。
更新日期:2020-07-01
中文翻译:
用于跨模态检索的深度监督多模态语义自动编码器
跨模态检索旨在在不同模态之间进行灵活的检索,其主要问题是如何衡量多模态数据之间的语义相似性。尽管已经提出了许多现有方法来实现跨模态检索,但它们很少考虑在多模态数据之间保留内容信息。在本文中,我们提出了一种名为 MMCA-CMR 的三阶段跨模态检索方法。为了减少多模态数据之间的差异,我们首先尝试将多模态数据嵌入到一个公共表示空间中。然后我们将特征向量与内容信息组合成语义感知特征向量。我们最终通过多模态语义自动编码器获得了特征感知和内容感知的投影。使用语义深度自动编码器,MMCA-CMR 通过同时学习来自不同模态和内容信息的特征向量,促进了更可靠的跨模态检索。大量实验表明,所提出的方法在跨模态检索中是有效的,在四个广泛使用的基准数据集上显着优于最先进的方法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号