当前位置:
X-MOL 学术
›
Comput. Animat. Virtual Worlds
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Automatic text‐to‐gesture rule generation for embodied conversational agents
Computer Animation and Virtual Worlds ( IF 0.9 ) Pub Date : 2020-07-01 , DOI: 10.1002/cav.1944 Ghazanfar Ali 1 , Myungho Lee 2 , Jae‐In Hwang 2
Computer Animation and Virtual Worlds ( IF 0.9 ) Pub Date : 2020-07-01 , DOI: 10.1002/cav.1944 Ghazanfar Ali 1 , Myungho Lee 2 , Jae‐In Hwang 2
Affiliation
|
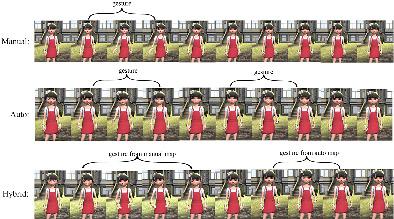
Interactions with embodied conversational agents can be enhanced using human‐like co‐speech gestures. Traditionally, rule‐based co‐speech gesture mapping has been utilized for this purpose. However, the creation of this mapping is laborious and often requires human experts. Moreover, human‐created mapping tends to be limited, therefore prone to generate repeated gestures. In this article, we present an approach to automate the generation of rule‐based co‐speech gesture mapping from publicly available large video data set without the intervention of human experts. At run‐time, word embedding is utilized for rule searching to get the semantic‐aware, meaningful, and accurate rule. The evaluation indicated that our method achieved comparable performance with the manual map generated by human experts, with a more variety of gestures activated. Moreover, synergy effects were observed in users' perception of generated co‐speech gestures when combined with the manual map.
中文翻译:

嵌入对话代理的自动文本到手势规则生成
可以使用类似人类的共同语音手势来增强与具体对话代理的交互。传统上,为此目的使用了基于规则的共同语音手势映射。但是,创建此映射很费力,而且通常需要人类专家。此外,人工创建的映射往往是有限的,因此容易产生重复的手势。在本文中,我们提出了一种无需人类专家干预即可从公开可用的大型视频数据集自动生成基于规则的协同语音手势映射的方法。在运行时,利用词嵌入进行规则搜索,以获得语义感知、有意义和准确的规则。评估表明,我们的方法实现了与人类专家生成的手动地图相当的性能,激活了更多种类的手势。而且,
更新日期:2020-07-01
中文翻译:
嵌入对话代理的自动文本到手势规则生成
可以使用类似人类的共同语音手势来增强与具体对话代理的交互。传统上,为此目的使用了基于规则的共同语音手势映射。但是,创建此映射很费力,而且通常需要人类专家。此外,人工创建的映射往往是有限的,因此容易产生重复的手势。在本文中,我们提出了一种无需人类专家干预即可从公开可用的大型视频数据集自动生成基于规则的协同语音手势映射的方法。在运行时,利用词嵌入进行规则搜索,以获得语义感知、有意义和准确的规则。评估表明,我们的方法实现了与人类专家生成的手动地图相当的性能,激活了更多种类的手势。而且,










































 京公网安备 11010802027423号
京公网安备 11010802027423号