当前位置:
X-MOL 学术
›
Environ. Sci. Technol.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Using Large-Scale NO2 Data from Citizen Science for Air-Quality Compliance and Policy Support.
Environmental Science & Technology ( IF 10.8 ) Pub Date : 2020-08-21 , DOI: 10.1021/acs.est.0c02436 Sam De Craemer 1, 2 , Jordy Vercauteren 3 , Frans Fierens 4 , Wouter Lefebvre 2 , Filip J R Meysman 1, 5
Environmental Science & Technology ( IF 10.8 ) Pub Date : 2020-08-21 , DOI: 10.1021/acs.est.0c02436 Sam De Craemer 1, 2 , Jordy Vercauteren 3 , Frans Fierens 4 , Wouter Lefebvre 2 , Filip J R Meysman 1, 5
Affiliation
|
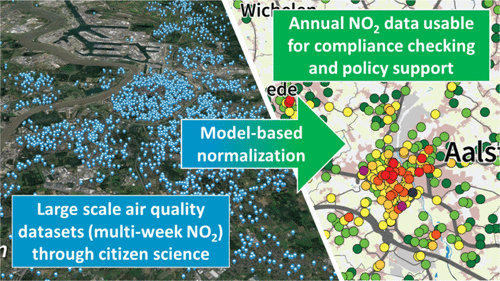
Citizen science projects that monitor air quality have recently drastically expanded in scale. Projects involving thousands of citizens generate spatially dense data sets using low-cost passive samplers for nitrogen dioxide (NO2), which complement data from the sparse reference network operated by environmental agencies. However, there is a critical bottleneck in using these citizen-derived data sets for air-quality policy. The monitoring effort typically lasts only a few weeks, while long-term air-quality guidelines are based on annual-averaged concentrations that are not affected by seasonal fluctuations in air quality. Here, we describe a statistical model approach to reliably transform passive sampler NO2 data from multiweek averages to annual-averaged values. The predictive model is trained with data from reference stations that are limited in number but provide full temporal coverage and is subsequently applied to the one-off data set recorded by the spatially extensive network of passive samplers. We verify the assumptions underlying the model procedure and demonstrate that model uncertainty complies with the EU-quality objectives for air-quality monitoring. Our approach allows a considerable cost optimization of passive sampler campaigns and removes a critical bottleneck for citizen-derived data to be used for compliance checking and air-quality policy use.
中文翻译:

使用Citizen Science的大规模NO2数据获得空气质量合规性和政策支持。
最近,监测空气质量的公民科学项目规模急剧扩大。涉及上千公民的项目生成使用低成本被动采样为二氧化氮(NO空间密集数据集2),其从稀疏参考网络补码数据由环境机构操作。但是,将这些公民衍生的数据集用于空气质量政策存在严重的瓶颈。监测工作通常仅持续数周,而长期空气质量指南则基于不受空气质量季节性波动影响的年平均浓度。在这里,我们描述了一种统计模型方法来可靠地转换无源采样器NO 2从多周平均值到年度平均值的数据。预测模型使用来自参考站的数据进行训练,该参考站的数量有限但提供了完整的时间覆盖范围,随后将其应用于由无源采样器的空间扩展网络记录的一次性数据集。我们验证了模型程序的基础假设,并证明模型不确定性符合欧盟质量目标中的空气质量监测目标。我们的方法可以极大地优化被动采样活动的成本,并消除了将公民衍生数据用于合规性检查和空气质量政策使用的关键瓶颈。
更新日期:2020-09-15
中文翻译:
使用Citizen Science的大规模NO2数据获得空气质量合规性和政策支持。
最近,监测空气质量的公民科学项目规模急剧扩大。涉及上千公民的项目生成使用低成本被动采样为二氧化氮(NO空间密集数据集2),其从稀疏参考网络补码数据由环境机构操作。但是,将这些公民衍生的数据集用于空气质量政策存在严重的瓶颈。监测工作通常仅持续数周,而长期空气质量指南则基于不受空气质量季节性波动影响的年平均浓度。在这里,我们描述了一种统计模型方法来可靠地转换无源采样器NO 2从多周平均值到年度平均值的数据。预测模型使用来自参考站的数据进行训练,该参考站的数量有限但提供了完整的时间覆盖范围,随后将其应用于由无源采样器的空间扩展网络记录的一次性数据集。我们验证了模型程序的基础假设,并证明模型不确定性符合欧盟质量目标中的空气质量监测目标。我们的方法可以极大地优化被动采样活动的成本,并消除了将公民衍生数据用于合规性检查和空气质量政策使用的关键瓶颈。










































 京公网安备 11010802027423号
京公网安备 11010802027423号