当前位置:
X-MOL 学术
›
React. Chem. Eng.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Iterative experimental design based on active machine learning reduces the experimental burden associated with reaction screening
Reaction Chemistry & Engineering ( IF 3.9 ) Pub Date : 2020-08-17 , DOI: 10.1039/d0re00232a Natalie S. Eyke 1, 2, 3, 4 , William H. Green 1, 2, 3, 4 , Klavs F. Jensen 1, 2, 3, 4
Reaction Chemistry & Engineering ( IF 3.9 ) Pub Date : 2020-08-17 , DOI: 10.1039/d0re00232a Natalie S. Eyke 1, 2, 3, 4 , William H. Green 1, 2, 3, 4 , Klavs F. Jensen 1, 2, 3, 4
Affiliation
|
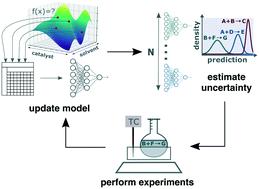
High-throughput reaction screening has emerged as a useful means of rapidly identifying the influence of key reaction variables on reaction outcomes. We show that active machine learning can further this objective by eliminating dependence on “exhaustive” screens (screens in which all possible combinations of the reaction variables of interest are examined). This is achieved through iterative selection of maximally informative experiments from the subset of all possible experiments in the domain. These experiments can be used to train accurate machine learning models that can be used to predict the outcomes of reactions that were not performed, thus reducing the overall experimental burden. To demonstrate our approach, we conduct retrospective analyses of the preexisting results of high-throughput reaction screening experiments. We compare the test set errors of models trained on actively-selected reactions to models trained on reactions selected at random from the same domain. We find that the degree to which models trained on actively-selected data outperform models trained on randomly-selected data depends on the domain being modeled, with it being possible to achieve very low test set errors when the dataset is heavily skewed in favor of low- or zero-yielding reactions. Our results confirm that this algorithm is a useful experiment planning tool that can change the reaction screening paradigm, by allowing medicinal and process chemists to focus their reaction screening efforts on the generation of a small amount of high-quality data.
中文翻译:

基于主动机器学习的迭代实验设计减少了与反应筛选相关的实验负担
高通量反应筛选已成为快速识别关键反应变量对反应结果的影响的有用手段。我们表明,主动机器学习可以消除对“穷举”屏幕(检查感兴趣的反应变量的所有可能组合的屏幕)的依赖,从而可以进一步实现这一目标。这是通过从域中所有可能的实验子集中迭代选择信息量最大的实验来实现的。这些实验可用于训练准确的机器学习模型,该模型可用于预测未执行的反应的结果,从而减少总体实验负担。为了证明我们的方法,我们对高通量反应筛选实验的先前结果进行了回顾性分析。我们将根据主动选择的反应训练的模型的测试集错误与根据相同领域随机选择的反应训练的模型进行比较。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。当数据集严重偏向低收益或零收益反应时,有可能实现非常低的测试集错误。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。当数据集严重偏向低收益或零收益反应时,有可能实现非常低的测试集错误。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。
更新日期:2020-09-29
中文翻译:
基于主动机器学习的迭代实验设计减少了与反应筛选相关的实验负担
高通量反应筛选已成为快速识别关键反应变量对反应结果的影响的有用手段。我们表明,主动机器学习可以消除对“穷举”屏幕(检查感兴趣的反应变量的所有可能组合的屏幕)的依赖,从而可以进一步实现这一目标。这是通过从域中所有可能的实验子集中迭代选择信息量最大的实验来实现的。这些实验可用于训练准确的机器学习模型,该模型可用于预测未执行的反应的结果,从而减少总体实验负担。为了证明我们的方法,我们对高通量反应筛选实验的先前结果进行了回顾性分析。我们将根据主动选择的反应训练的模型的测试集错误与根据相同领域随机选择的反应训练的模型进行比较。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。我们发现,在主动选择的数据上训练的模型优于在随机选择的数据上训练的模型的程度取决于要建模的域,当数据集严重偏向低值时,有可能实现非常低的测试集错误-或零收益反应。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。当数据集严重偏向低收益或零收益反应时,有可能实现非常低的测试集错误。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。当数据集严重偏向低收益或零收益反应时,有可能实现非常低的测试集错误。我们的结果证实,该算法是一种有用的实验计划工具,它可以通过允许医学和过程化学家将他们的反应筛选工作重点放在生成少量高质量数据上来更改反应筛选范例。


























 京公网安备 11010802027423号
京公网安备 11010802027423号