当前位置:
X-MOL 学术
›
J. Softw. Evol. Process
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Using software metrics for predicting vulnerable classes and methods in Java projects: A machine learning approach
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2020-08-07 , DOI: 10.1002/smr.2303 Kazi Zakia Sultana 1 , Vaibhav Anu 1 , Tai‐Yin Chong 1
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2020-08-07 , DOI: 10.1002/smr.2303 Kazi Zakia Sultana 1 , Vaibhav Anu 1 , Tai‐Yin Chong 1
Affiliation
|
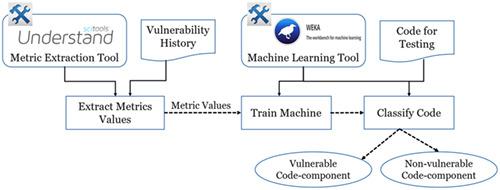
[Context]A software vulnerability becomes harmful for software when an attacker successfully exploits the insecure code and reveals the vulnerability. A single vulnerability in code can put the entire software at risk. Therefore, maintaining software security throughout the software life cycle is an important and at the same time challenging task for development teams. This can also leave the door open for vulnerable code being evolved during successive releases. In recent years, researchers have used software metrics‐based vulnerability prediction approaches to detect vulnerable code early and ensure secure code releases. Software metrics have been employed to predict vulnerability specifically in C/C++ and Java‐based systems. However, the prediction performance of metrics at different granularity levels (class level or method level) has not been analyzed. In this paper, we focused on metrics that are specific to lower granularity levels (Java classes and methods). Based on statistical analysis, we first identified a set of class‐level metrics and a set of method‐level metrics and then employed them as features in machine learning techniques to predict vulnerable classes and methods, respectively. This paper describes a comparative study on how our selected metrics perform at different granularity levels. Such a comparative study can help the developers in choosing the appropriate metrics (at the desired level of granularity). [Objective] The goal of this research is to propose a set of metrics at two lower granularity levels and provide evidence for their usefulness during vulnerability prediction (which will help in maintaining secure code and ensure secure software evolution). [Method] For four Java‐based open source systems (including two releases of Apache Tomcat), we designed and conducted experiments based on statistical tests to propose a set of software metrics that can be used for predicting vulnerable code components (i.e., vulnerable classes and methods). Next, we used our identified metrics as features to train supervised machine learning algorithms to classify Java code as vulnerable or non‐vulnerable. [Result] Our study has successfully identified a set of class‐level metrics and a second set of method‐level metrics that can be useful from a vulnerability prediction standpoint. We achieved recall higher than 70% and precision higher than 75% in vulnerability prediction using our identified class‐level metrics as features of machine learning. Furthermore, method‐level metrics showed recall higher than 65% and precision higher than 80%.
中文翻译:

使用软件指标预测Java项目中的易受攻击的类和方法:一种机器学习方法
[上下文当攻击者成功利用不安全的代码并揭示该漏洞时,软件漏洞对软件有害。代码中的单个漏洞可能会使整个软件面临风险。因此,在整个软件生命周期中维护软件安全性对于开发团队而言是一项重要且同时具有挑战性的任务。这也可能为在后续发行版中演化出易受攻击的代码敞开大门。近年来,研究人员已使用基于软件指标的漏洞预测方法来及早发现易受攻击的代码并确保安全的代码发布。已使用软件指标来专门预测C / C ++和基于Java的系统中的漏洞。然而,尚未分析不同粒度级别(类级别或方法级别)的指标的预测性能。在本文中,我们专注于特定于较低粒度级别的指标(Java类和方法)。基于统计分析,我们首先确定一组类级别的度量标准和一组方法级别的度量标准,然后将它们用作机器学习技术的功能,分别预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 我们首先确定了一组类级别的度量标准和一组方法级别的度量标准,然后将它们作为机器学习技术的功能分别用于预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 我们首先确定了一组类级别的度量标准和一组方法级别的度量标准,然后将它们作为机器学习技术的功能分别用于预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[[目的]这项研究的目的是在两个较低的粒度级别上提出一组度量标准,并为它们在漏洞预测中的有用性提供证据(这将有助于维护安全的代码并确保软件的安全演化)。[方法]对于四个基于Java的开源系统(包括两个版本的Apache Tomcat),我们基于统计测试设计并进行了实验,提出了一套可用于预测易受攻击的代码组件(即易受攻击的类)的软件指标。和方法)。接下来,我们将确定的指标用作培训受监督的机器学习算法的功能,以将Java代码分类为易受攻击或不易受攻击。[结果]我们的研究成功地确定了一组类级别的度量标准和第二套方法级别的度量标准,它们从漏洞预测的角度来看可能是有用的。通过使用我们确定的类级指标作为机器学习的功能,我们在漏洞预测中实现了70%以上的召回率和75%以上的精度。此外,方法级指标显示召回率高于65%,准确度高于80%。
更新日期:2020-08-07
中文翻译:
使用软件指标预测Java项目中的易受攻击的类和方法:一种机器学习方法
[上下文当攻击者成功利用不安全的代码并揭示该漏洞时,软件漏洞对软件有害。代码中的单个漏洞可能会使整个软件面临风险。因此,在整个软件生命周期中维护软件安全性对于开发团队而言是一项重要且同时具有挑战性的任务。这也可能为在后续发行版中演化出易受攻击的代码敞开大门。近年来,研究人员已使用基于软件指标的漏洞预测方法来及早发现易受攻击的代码并确保安全的代码发布。已使用软件指标来专门预测C / C ++和基于Java的系统中的漏洞。然而,尚未分析不同粒度级别(类级别或方法级别)的指标的预测性能。在本文中,我们专注于特定于较低粒度级别的指标(Java类和方法)。基于统计分析,我们首先确定一组类级别的度量标准和一组方法级别的度量标准,然后将它们用作机器学习技术的功能,分别预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 我们首先确定了一组类级别的度量标准和一组方法级别的度量标准,然后将它们作为机器学习技术的功能分别用于预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 我们首先确定了一组类级别的度量标准和一组方法级别的度量标准,然后将它们作为机器学习技术的功能分别用于预测易受攻击的类和方法。本文介绍了有关我们所选指标如何在不同粒度级别上执行的比较研究。这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[ 这样的比较研究可以帮助开发人员选择适当的度量标准(以所需的粒度级别)。[[目的]这项研究的目的是在两个较低的粒度级别上提出一组度量标准,并为它们在漏洞预测中的有用性提供证据(这将有助于维护安全的代码并确保软件的安全演化)。[方法]对于四个基于Java的开源系统(包括两个版本的Apache Tomcat),我们基于统计测试设计并进行了实验,提出了一套可用于预测易受攻击的代码组件(即易受攻击的类)的软件指标。和方法)。接下来,我们将确定的指标用作培训受监督的机器学习算法的功能,以将Java代码分类为易受攻击或不易受攻击。[结果]我们的研究成功地确定了一组类级别的度量标准和第二套方法级别的度量标准,它们从漏洞预测的角度来看可能是有用的。通过使用我们确定的类级指标作为机器学习的功能,我们在漏洞预测中实现了70%以上的召回率和75%以上的精度。此外,方法级指标显示召回率高于65%,准确度高于80%。








































 京公网安备 11010802027423号
京公网安备 11010802027423号