当前位置:
X-MOL 学术
›
RSC Med. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Active learning effectively identifies a minimal set of maximally informative and asymptotically performant cytotoxic structure–activity patterns in NCI-60 cell lines
RSC Medicinal Chemistry ( IF 4.1 ) Pub Date : 2020-07-20 , DOI: 10.1039/d0md00110d Takumi Nakano 1 , Shunichi Takeda 2 , J B Brown 1
RSC Medicinal Chemistry ( IF 4.1 ) Pub Date : 2020-07-20 , DOI: 10.1039/d0md00110d Takumi Nakano 1 , Shunichi Takeda 2 , J B Brown 1
Affiliation
|
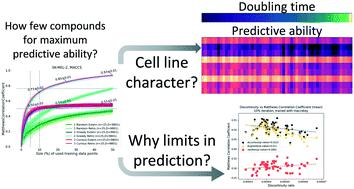
The NCI-60 cancer cell line screening panel has provided insights for development of subtype-specific chemical therapies and repurposing. By extracting chemical structure and cytotoxicity patterns, virtual screening potentially complements the availability of high-throughput assay platforms and improves bioactive compound discovery rates by computational prefiltering of candidate compound libraries. Many groups report high prediction performances in computational models of NCI-60 data when using cross-validation or similar techniques, yet prospective therapy development in novel cancers may have little to no such data and further may not have the resources to perform hit identification using large compound libraries. In contrast to bulk screening and analysis, the active learning methodology has demonstrated how to identify compounds for screening in small batches and update computational models iteratively, leading to predictive models with a minimum number of compounds, and importantly clarifying data volumes at which limits in predictive ability are achieved. Here, in replicate per-cell line experiments using 50% of data (∼20 000 compounds) as the external prediction target, predictive limits are reproducibly demonstrated at the stage of systematic selection of 10–30% of the incorporable half. The pattern was consistent across all 60 cell lines. Limits of predictability are found to be correlated to the doubling times of cell lines and the number of cellular response discontinuities (activity cliffs) present per cell line. Organization into chemical scaffolds delineated degrees of predictive challenge. These results provide key insights for strategies in developing new inhibitors in existing cell lines or for future automated therapy selection in personalized oncotherapy.
中文翻译:

主动学习有效地识别了 NCI-60 细胞系中一组信息量最大且渐近表现的细胞毒性结构-活性模式的最小集合
NCI-60 癌细胞系筛选小组为亚型特异性化学疗法的开发和重新利用提供了见解。通过提取化学结构和细胞毒性模式,虚拟筛选可能补充高通量检测平台的可用性,并通过候选化合物库的计算预过滤提高生物活性化合物的发现率。许多小组报告在使用交叉验证或类似技术时,NCI-60 数据的计算模型具有较高的预测性能,但新型癌症的前瞻性治疗开发可能几乎没有或没有此类数据,而且可能没有资源使用大量数据来执行命中识别。化合物库。与批量筛选和分析相比,主动学习方法展示了如何识别用于小批量筛选的化合物并迭代更新计算模型,从而产生具有最少化合物数量的预测模型,并且重要的是阐明了预测的数据量限制能力得到实现。在这里,在使用 50% 的数据(∼20 000 种化合物)作为外部预测目标的重复每细胞系实验中,在系统选择 10-30% 的不可合并一半的阶段,可重复地证明了预测极限。该模式在所有 60 个细胞系中都是一致的。发现可预测性的限制与细胞系的倍增时间和每个细胞系存在的细胞反应不连续性(活动悬崖)的数量相关。组织成化学支架描绘了预测挑战的程度。这些结果为在现有细胞系中开发新抑制剂的策略或未来个性化肿瘤治疗中的自动化治疗选择提供了重要见解。
更新日期:2020-09-23
中文翻译:
主动学习有效地识别了 NCI-60 细胞系中一组信息量最大且渐近表现的细胞毒性结构-活性模式的最小集合
NCI-60 癌细胞系筛选小组为亚型特异性化学疗法的开发和重新利用提供了见解。通过提取化学结构和细胞毒性模式,虚拟筛选可能补充高通量检测平台的可用性,并通过候选化合物库的计算预过滤提高生物活性化合物的发现率。许多小组报告在使用交叉验证或类似技术时,NCI-60 数据的计算模型具有较高的预测性能,但新型癌症的前瞻性治疗开发可能几乎没有或没有此类数据,而且可能没有资源使用大量数据来执行命中识别。化合物库。与批量筛选和分析相比,主动学习方法展示了如何识别用于小批量筛选的化合物并迭代更新计算模型,从而产生具有最少化合物数量的预测模型,并且重要的是阐明了预测的数据量限制能力得到实现。在这里,在使用 50% 的数据(∼20 000 种化合物)作为外部预测目标的重复每细胞系实验中,在系统选择 10-30% 的不可合并一半的阶段,可重复地证明了预测极限。该模式在所有 60 个细胞系中都是一致的。发现可预测性的限制与细胞系的倍增时间和每个细胞系存在的细胞反应不连续性(活动悬崖)的数量相关。组织成化学支架描绘了预测挑战的程度。这些结果为在现有细胞系中开发新抑制剂的策略或未来个性化肿瘤治疗中的自动化治疗选择提供了重要见解。










































 京公网安备 11010802027423号
京公网安备 11010802027423号