Computer Methods and Programs in Biomedicine ( IF 4.9 ) Pub Date : 2020-07-11 , DOI: 10.1016/j.cmpb.2020.105645 Yusuf Yargı Baydilli 1 , Umit Atila 1 , Abdullah Elen 2
|
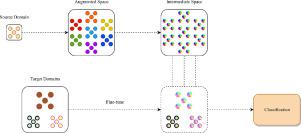
Background and objective: Traditional machine learning methods assume that both training and test data come from the same distribution. In this way, it becomes possible to achieve high successes when modelling on the same domain. Unfortunately, in real-world problems, direct transfer between domains is adversely affected due to differences in the data collection process and the internal dynamics of the data. In order to cope with such drawbacks, researchers use a method called “domain adaptation”, which enables the successful transfer of information learned in one domain to other domains. In this study, a model that can be used in the classification of white blood cells (WBC) and is not affected by domain differences was proposed.
Methods: Only one data set was used as source domain, and an adaptation process was created that made possible the learned knowledge to be used effectively in other domains (multi-target domain adaptation). While constructing the model, we employed data augmentation, data generation and fine-tuning processes, respectively.
Results: The proposed model has been able to extract “domain-invariant” features and achieved high success rates in the tests performed on nine different data sets. Multi-target domain adaptation accuracy was measured as %98.09.
Conclusions: At the end of the study, it has been observed that the proposed model ignores the domain differences and it can adapt in a successful way to target domains. In this way, it becomes possible to classify unlabeled samples rapidly by using only a few number of labeled ones.
中文翻译:
从一个数据集中学习以对所有事物进行分类-一种用于白细胞分类的多目标域适应方法。
背景和目标:传统的机器学习方法假设训练和测试数据都来自同一分布。这样,在同一域上建模时,可以获得很高的成功。不幸的是,在实际问题中,由于数据收集过程和数据内部动态的差异,域之间的直接传输受到不利影响。为了解决这些缺点,研究人员使用了一种称为“领域适应”的方法,该方法可以将在一个领域中学习到的信息成功地转移到其他领域。在这项研究中,提出了一种可用于白细胞分类(WBC)且不受域差异影响的模型。
方法:仅将一个数据集用作源域,并且创建了一个适应过程,使学习到的知识可以有效地用于其他域(多目标域适应)。在构建模型时,我们分别采用了数据扩充,数据生成和微调过程。
结果:所提出的模型已经能够提取“领域不变”特征,并且在针对9个不同数据集进行的测试中获得了很高的成功率。测量的多目标域适应精度为%98.09。
结论:在研究结束时,已观察到所提出的模型忽略了域差异,并且可以成功地适应目标域。这样,通过仅使用少量的标记样品就可以对未标记样品进行快速分类。










































 京公网安备 11010802027423号
京公网安备 11010802027423号