Water Research ( IF 11.4 ) Pub Date : 2020-06-30 , DOI: 10.1016/j.watres.2020.116103 Run-Ze Xu 1 , Jia-Shun Cao 2 , Yang Wu 1 , Su-Na Wang 1 , Jing-Yang Luo 2 , Xueming Chen 3 , Fang Fang 2
|
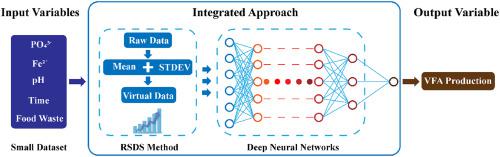
Data-driven models are suitable for simulating biological wastewater treatment processes with complex intrinsic mechanisms. However, raw data collected in the early stage of biological experiments are normally not enough to train data-driven models. In this study, an integrated modeling approach incorporating the random standard deviation sampling (RSDS) method and deep neural networks (DNNs) models, was established to predict volatile fatty acid (VFA) production in the anaerobic fermentation process. The RSDS method based on the mean values () and standard deviations (α) calculated from multiple experimental determination was initially developed for virtual data augmentation. The DNNs models were then established to learn features from virtual data and predict VFA production. The results showed that when 20000 virtual samples including five input variables of the anaerobic fermentation process were used to train the DNNs model with 16 hidden layers and 100 hidden neurons in each layer, the best correlation coefficient of 0.998 and the minimal mean absolute percentage error of 3.28% were achieved. This integrated approach can learn nonlinear information from virtual data generated by the RSDS method, and consequently enlarge the application range of DNNs models in simulating biological wastewater treatment processes with small datasets.
中文翻译:
基于虚拟数据增强和深度神经网络建模的厌氧发酵过程中VFA产量预测的集成方法。
数据驱动模型适用于模拟具有复杂内在机制的生物废水处理过程。但是,在生物学实验的早期阶段收集的原始数据通常不足以训练数据驱动的模型。在这项研究中,建立了一种综合的建模方法,该方法结合了随机标准差采样(RSDS)方法和深度神经网络(DNN)模型,以预测厌氧发酵过程中挥发性脂肪酸(VFA)的产生。基于平均值的RSDS方法(),然后首先通过多次实验确定得出的标准差(α)用于虚拟数据扩充。然后建立DNN模型以从虚拟数据中学习特征并预测VFA产生。结果表明,当使用20000个虚拟样本(包括五个厌氧发酵过程的输入变量)训练DNNs模型时,每层具有16个隐藏层和100个隐藏神经元时,最佳相关系数为0.998,最小平均绝对百分比误差为1。达到3.28%。这种集成的方法可以从RSDS方法生成的虚拟数据中学习非线性信息,从而扩大了DNNs模型在模拟具有小数据集的生物废水处理过程中的应用范围。










































 京公网安备 11010802027423号
京公网安备 11010802027423号