当前位置:
X-MOL 学术
›
Comput. Electr. Eng.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Improving malware detection using big data and ensemble learning
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-09-01 , DOI: 10.1016/j.compeleceng.2020.106729 Deepak Gupta , Rinkle Rani
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-09-01 , DOI: 10.1016/j.compeleceng.2020.106729 Deepak Gupta , Rinkle Rani
|
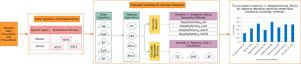
Abstract Malware detection and classification play a critical role in computer and network security. Although, many machine learning models have been used in the detection of malicious binaries, however, the performance of ensemble methods has not been investigated extensively. Besides, the massive volume of malware has established it as a big data problem forcing security researchers and practitioners to deploy big data technologies to manage, store, analyze, and visualize malware data. In this paper, the authors have designed two methods based on ensemble learning and big data for improving the performance of malware detection at a large scale. The first method is based on the weighted voting strategy of ensemble learning, and the second method chooses an optimal set of base classifiers for stacking purpose. The proposed methods are implemented using Apache Spark, a popular big data processing framework, and their performance is tested and evaluated on a dataset of 198,350 Windows files including 100,200 malicious and 98,150 benign samples. The experimental results successfully validate the effectiveness of the proposed approach since it improves the generalization performance in detecting new malware.
中文翻译:

使用大数据和集成学习改进恶意软件检测
摘要 恶意软件检测和分类在计算机和网络安全中起着至关重要的作用。尽管许多机器学习模型已用于检测恶意二进制文件,但集成方法的性能尚未得到广泛研究。此外,大量恶意软件已将其确定为一个大数据问题,迫使安全研究人员和从业人员部署大数据技术来管理、存储、分析和可视化恶意软件数据。在本文中,作者设计了两种基于集成学习和大数据的方法来大规模提高恶意软件检测的性能。第一种方法基于集成学习的加权投票策略,第二种方法选择一组最优的基分类器进行堆叠。所提出的方法使用流行的大数据处理框架 Apache Spark 实现,并在 198,350 个 Windows 文件的数据集上测试和评估其性能,其中包括 100,200 个恶意样本和 98,150 个良性样本。实验结果成功地验证了所提出方法的有效性,因为它提高了检测新恶意软件的泛化性能。
更新日期:2020-09-01
中文翻译:
使用大数据和集成学习改进恶意软件检测
摘要 恶意软件检测和分类在计算机和网络安全中起着至关重要的作用。尽管许多机器学习模型已用于检测恶意二进制文件,但集成方法的性能尚未得到广泛研究。此外,大量恶意软件已将其确定为一个大数据问题,迫使安全研究人员和从业人员部署大数据技术来管理、存储、分析和可视化恶意软件数据。在本文中,作者设计了两种基于集成学习和大数据的方法来大规模提高恶意软件检测的性能。第一种方法基于集成学习的加权投票策略,第二种方法选择一组最优的基分类器进行堆叠。所提出的方法使用流行的大数据处理框架 Apache Spark 实现,并在 198,350 个 Windows 文件的数据集上测试和评估其性能,其中包括 100,200 个恶意样本和 98,150 个良性样本。实验结果成功地验证了所提出方法的有效性,因为它提高了检测新恶意软件的泛化性能。










































 京公网安备 11010802027423号
京公网安备 11010802027423号