Current Proteomics ( IF 0.8 ) Pub Date : 2020-07-31 , DOI: 10.2174/1570164616666190722141129 Gaofeng Pan 1 , Jiandong Wang 1 , Liang Zhao 1 , William Hoskins 1 , Jijun Tang 1
|
Background: DNA-binding proteins are very important to many biomolecular functions. The traditional experimental methods are expensive and time-consuming, so, computational methods that can predict whether a protein is a DNA-binding protein or not are very helpful to researchers. Machine learning has been widely used in many research areas. Many researchers have proposed machine learning methods for DNA-binding protein prediction, and this paper highlights their advantages and disadvantages.
Objective: There are many computational methods that can predict DNA-binding proteins. Every method uses different features and different classifier algorithms. In this paper, a review of these methods is provided to find out some common procedures that can help researchers to develop more accurate methods.
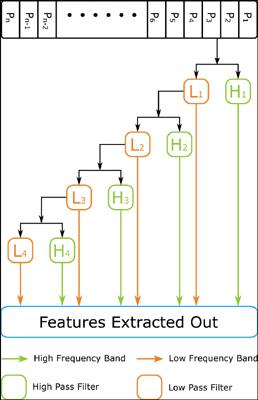
Methods: Firstly, the information stored in the protein sequence and gene sequence is presented. That information is the basis to find out the patterns leading to binding. Then, feature extraction methods and classifier algorithms are discussed. At last, some commonly used benchmark datasets are analysed and evaluated by methods.
Conclusion: In this review, we analyzed some popular computational methods to predict DNAbinding protein. From those methods, we highlighted many features necessary to build up an accurate DNA-binding protein classifier. This can also help researchers to build up more useful computational tools. Currently, there are some machine learning methods with good performance in predicting DNAbinding proteins. The performance can be improved by using different kinds of features and classifiers.
中文翻译:
预测DNA结合蛋白的计算方法
背景:DNA结合蛋白对许多生物分子功能非常重要。传统的实验方法昂贵且费时,因此可以预测蛋白质是否为DNA结合蛋白的计算方法对研究人员非常有用。机器学习已广泛应用于许多研究领域。许多研究人员提出了用于DNA结合蛋白预测的机器学习方法,本文重点介绍了它们的优缺点。
目的:有许多可以预测DNA结合蛋白的计算方法。每种方法使用不同的功能和不同的分类器算法。在本文中,对这些方法进行了综述,以找出一些可以帮助研究人员开发更准确方法的常用程序。
方法:首先,介绍了蛋白质序列和基因序列中存储的信息。该信息是找出导致绑定的模式的基础。然后,讨论了特征提取方法和分类器算法。最后,通过方法对一些常用的基准数据集进行了分析和评估。
结论:在这篇综述中,我们分析了一些流行的计算方法来预测DNA结合蛋白。通过这些方法,我们强调了构建准确的DNA结合蛋白分类器所必需的许多功能。这也可以帮助研究人员建立更多有用的计算工具。当前,存在一些在预测DNA结合蛋白方面具有良好性能的机器学习方法。通过使用不同种类的功能和分类器,可以提高性能。


























 京公网安备 11010802027423号
京公网安备 11010802027423号