Environment International ( IF 10.3 ) Pub Date : 2020-06-25 , DOI: 10.1016/j.envint.2020.105827 Xiang Ren 1 , Zhongyuan Mi 2 , Panos G Georgopoulos 3
|
Background
Spatial linear Land-Use Regression (LUR) is commonly used for long-term modeling of air pollution in support of exposure and epidemiological assessments. Machine Learning (ML) methods in conjunction with spatiotemporal modeling can provide more flexible exposure-relevant metrics and have been studied using different model structures. There is however a lack of comparisons of methods available within these two modeling frameworks, that can guide model/algorithm selection in air quality epidemiology.
Objective
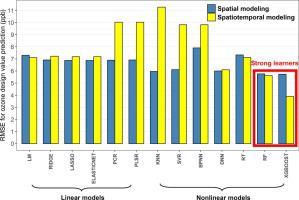
The present study compares thirteen algorithms for spatial/spatiotemporal modeling applied for daily maxima of 8-hour running averages of ambient ozone concentrations at spatial resolutions corresponding to census tracts, to support estimation of annual ozone design values across the contiguous US. These algorithms were selected from nine representative categories and trained using predictors that included chemistry-transport model predictions, meteorological factors, land use and land cover, and stationary and mobile emissions.
Methods
To obtain the best predictive performance, model structures were optimized through a repeated coarse/fine grid search with expert knowledge. Six target-oriented validation strategies were used to prevent overfitting and avoid over-optimistic model evaluation results. In order to take full advantage of the power of different algorithms, we introduced tuning sample weights in spatiotemporal modeling to ensure predictive accuracy of peak concentrations, that is crucial for exposure assessments. In spatial modeling, four interpretation and visualization tools were introduced to explain predictions from different algorithms.
Results
Nonlinear ML methods achieved higher prediction accuracy than linear LUR, and the improvements were more significant for spatiotemporal modeling (nearly 10%-40% decrease of predicted RMSE). By tuning the sample weights, spatiotemporal models can predict concentrations used to calculate ozone design values that are comparable or even better than spatial models (nearly 30% decrease of cross-validated RMSE). We visualized the underlying nonlinear relationships, heterogeneous associations and complex interactions from the two best performing ML algorithms, i.e., Random Forest and Extreme Gradient Boosting, and found that the complex patterns were relatively less significant with respect to model accuracy for spatial modeling.
Conclusion
Machine Learning can provide estimates that are actually more interpretable and practical than linear regression to improve accuracy in modeling human exposures. A careful design of hyperparameter tuning and flexible data splitting and validations is crucial to obtain reliable and stable results. Desirable/successful nonlinear models are expected to capture similar nonlinear patterns and interactions using different ML algorithms.
中文翻译:
机器学习和土地利用回归的比较,用于环境空气污染的精细时空估计:对整个美国的臭氧浓度进行建模。
背景
空间线性土地利用回归(LUR)通常用于空气污染的长期建模,以支持暴露和流行病学评估。结合时空建模的机器学习(ML)方法可以提供更灵活的与曝光相关的指标,并且已经使用不同的模型结构进行了研究。但是,在这两个建模框架内缺乏可用于指导空气质量流行病学模型/算法选择的方法的比较。
目的
本研究比较了十三种空间/时空建模算法,这些算法适用于每天八小时的环境臭氧浓度平均运行平均值,且对应于人口普查的空间分辨率,以支持估算连续美国的年度臭氧设计值。这些算法从9个代表性类别中进行选择,并使用包括化学运输模型预测,气象因素,土地利用和土地覆盖以及固定和移动排放在内的预测器进行了训练。
方法
为了获得最佳的预测性能,通过使用专家知识进行反复的粗/细网格搜索来优化模型结构。六种面向目标的验证策略被用来防止过度拟合并避免模型评估结果过于乐观。为了充分利用不同算法的功能,我们在时空建模中引入了调整样本权重的方法,以确保峰值浓度的预测准确性,这对于暴露评估至关重要。在空间建模中,引入了四种解释和可视化工具来解释来自不同算法的预测。
结果
非线性ML方法比线性LUR获得更高的预测精度,并且对时空建模的改进更为显着(预测的RMSE降低了近10%-40%)。通过调整样本权重,时空模型可以预测用于计算臭氧设计值的浓度,该浓度与空间模型相当甚至更好(交叉验证的RMSE减少了近30%)。我们将两种表现最佳的ML算法(即随机森林算法和极端梯度增强算法)的潜在非线性关系,异构关联和复杂相互作用可视化,发现对于空间建模,复杂模式相对不那么重要。
结论
机器学习可以提供比线性回归实际上更具解释性和实用性的估计,以提高建模人类暴露的准确性。精心设计超参数调整以及灵活的数据分割和验证对于获得可靠和稳定的结果至关重要。期望/成功的非线性模型将使用不同的ML算法捕获相似的非线性模式和相互作用。










































 京公网安备 11010802027423号
京公网安备 11010802027423号