当前位置:
X-MOL 学术
›
J. Phys. Chem. B
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Predicting Crystallization Tendency of Polymers Using Multifidelity Information Fusion and Machine Learning.
The Journal of Physical Chemistry B ( IF 2.8 ) Pub Date : 2020-06-15 , DOI: 10.1021/acs.jpcb.0c01865 Shruti Venkatram 1 , Rohit Batra 1 , Lihua Chen 1 , Chiho Kim 1 , Madeline Shelton 1 , Rampi Ramprasad 1
The Journal of Physical Chemistry B ( IF 2.8 ) Pub Date : 2020-06-15 , DOI: 10.1021/acs.jpcb.0c01865 Shruti Venkatram 1 , Rohit Batra 1 , Lihua Chen 1 , Chiho Kim 1 , Madeline Shelton 1 , Rampi Ramprasad 1
Affiliation
|
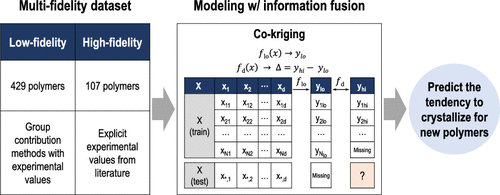
The degree of crystallinity of a polymer is a critical parameter that controls a variety of polymer properties. A high degree of crystallinity is associated with excellent mechanical properties crucial for high-performing applications like composites. Low crystallinity promotes ion and gas mobility critical for battery and membrane applications. Experimental determination of the crystallinity for new polymers is time and cost intensive. A data-driven machine learning-based method capable of rapidly predicting the crystallinity could counter these disadvantages and be used to screen polymers for a myriad of applications in a fast, inexpensive fashion. In this work, we developed the first-of-its-kind, data-driven machine learning model to predict the most-likely polymer crystallinity trained on experimental data and theoretical group contribution methods. Since polymer data under consistent processing conditions are unavailable, we tackled process variability by using the “most-likely” polymer values which we refer to as the polymer’s tendency to crystallize. Experimental data for polymers’ tendency to crystallize is limited by number and diversity, and to tackle this, we augmented experimentation-based data with data using group contribution methods. Therefore, this work utilized two data sets, viz., a high-fidelity, experimental data set for 107 polymers and a more diverse, less accurate low-fidelity data set for 429 polymers which used group contribution methods. We used a multifidelity information fusion strategy to utilize all the information captured in the low-fidelity data set while still predicting at the high-fidelity accuracy. Although this model inherently assumed “typical” processing conditions and estimated the “most-likely” percent crystallinity value, it can help in the estimation of a polymer’s tendency to crystallize in a far more cost-effective and efficient manner.
中文翻译:

使用多保真度信息融合和机器学习预测聚合物的结晶趋势。
聚合物的结晶度是控制多种聚合物性质的关键参数。高度的结晶度与出色的机械性能相关,这些性能对于复合材料等高性能应用至关重要。低结晶度会促进离子和气体迁移率,这对于电池和膜应用至关重要。新聚合物的结晶度的实验确定需要大量时间和成本。能够快速预测结晶度的基于数据驱动的基于机器学习的方法可以克服这些缺点,并可以以快速,廉价的方式筛选聚合物用于多种应用。在这项工作中,我们开发了首创的 数据驱动的机器学习模型,以预测最有可能在实验数据和理论基团贡献方法上训练的聚合物结晶度。由于无法获得在一致的加工条件下的聚合物数据,因此我们通过使用“最可能”的聚合物值(称为聚合物的结晶趋势)解决了工艺变异性。聚合物结晶趋势的实验数据受到数量和多样性的限制,为了解决这一问题,我们使用基团贡献方法对基于实验的数据进行了扩充。因此,这项工作利用了两个数据集,即107种聚合物的高保真性实验数据集和429种使用基团贡献法的较不精确的低保真度数据集。我们使用了多保真度信息融合策略来利用在低保真度数据集中捕获的所有信息,同时仍以高保真度进行预测。尽管此模型固有地假定“典型”加工条件并估算了“最可能”的结晶度百分比,但它可以帮助以更经济高效的方式估算聚合物的结晶趋势。
更新日期:2020-07-16
中文翻译:
使用多保真度信息融合和机器学习预测聚合物的结晶趋势。
聚合物的结晶度是控制多种聚合物性质的关键参数。高度的结晶度与出色的机械性能相关,这些性能对于复合材料等高性能应用至关重要。低结晶度会促进离子和气体迁移率,这对于电池和膜应用至关重要。新聚合物的结晶度的实验确定需要大量时间和成本。能够快速预测结晶度的基于数据驱动的基于机器学习的方法可以克服这些缺点,并可以以快速,廉价的方式筛选聚合物用于多种应用。在这项工作中,我们开发了首创的 数据驱动的机器学习模型,以预测最有可能在实验数据和理论基团贡献方法上训练的聚合物结晶度。由于无法获得在一致的加工条件下的聚合物数据,因此我们通过使用“最可能”的聚合物值(称为聚合物的结晶趋势)解决了工艺变异性。聚合物结晶趋势的实验数据受到数量和多样性的限制,为了解决这一问题,我们使用基团贡献方法对基于实验的数据进行了扩充。因此,这项工作利用了两个数据集,即107种聚合物的高保真性实验数据集和429种使用基团贡献法的较不精确的低保真度数据集。我们使用了多保真度信息融合策略来利用在低保真度数据集中捕获的所有信息,同时仍以高保真度进行预测。尽管此模型固有地假定“典型”加工条件并估算了“最可能”的结晶度百分比,但它可以帮助以更经济高效的方式估算聚合物的结晶趋势。










































 京公网安备 11010802027423号
京公网安备 11010802027423号