Human-centric Computing and Information Sciences ( IF 3.9 ) Pub Date : 2020-06-16 , DOI: 10.1186/s13673-020-00229-7 Dong-Gun Lee , Yeong-Seok Seo
|
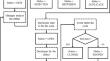
Artificial intelligence is one of the key technologies for progression to the fourth industrial revolution. This technology also has a significant impact on software professionals who are continuously striving to achieve high-quality software development by fixing various types of software bugs. During the software development and maintenance stages, software bugs are the major factor that can affect the cost and time of software delivery. To efficiently fix a software bug, open bug repositories are used for identifying bug reports and for classifying and prioritizing the reports for assignment to the most appropriate software developers based on their level of interest and expertise. Owing to a lack of resources such as time and manpower, this bug report triage process is extremely important in software development. To improve the bug report triage performance, numerous studies have focused on a latent Dirichlet allocation (LDA) using the k-nearest neighbors or a support vector machine. Although the existing approaches have improved the accuracy of a bug triage, they often cause conflicts between the combined techniques and generate incorrect triage results. In this study, we propose a method for improving the bug report triage performance using multiple LDA-based topic sets by improving the LDA. The proposed method improves the existing topic sets of the LDA by building two adjunct topic sets. In our experiment, we collected bug reports from a popular bug tracking system, Bugzilla, as well as Android bug reports, to evaluate the proposed method and demonstrate the achievement of the following two goals: increase the bug report triage accuracy, and satisfy the compatibility with other state-of-the-art approaches.
中文翻译:
使用基于人工智能的文档生成模型提高错误报告分类性能
人工智能是迈向第四次工业革命的关键技术之一。这项技术也对软件专业人员产生了重大影响,他们不断努力通过修复各种类型的软件错误来实现高质量的软件开发。在软件开发和维护阶段,软件缺陷是影响软件交付成本和时间的主要因素。为了有效地修复软件错误,开放的错误存储库用于识别错误报告并对报告进行分类和优先级排序,以便根据他们的兴趣和专业知识水平分配给最合适的软件开发人员。由于缺乏时间和人力等资源,错误报告分类过程在软件开发中极其重要。为了提高错误报告分类性能,许多研究都集中在使用 k 最近邻或支持向量机的潜在狄利克雷分配 (LDA)。尽管现有方法提高了错误分类的准确性,但它们经常会导致组合技术之间的冲突并产生错误的分类结果。在本研究中,我们提出了一种通过改进 LDA 来使用多个基于 LDA 的主题集来提高错误报告分类性能的方法。该方法通过构建两个附加主题集来改进 LDA 的现有主题集。在我们的实验中,我们收集了来自流行的错误跟踪系统 Bugzilla 的错误报告以及 Android 错误报告,以评估所提出的方法并演示以下两个目标的实现:提高错误报告分类准确性,并满足兼容性与其他最先进的方法。










































 京公网安备 11010802027423号
京公网安备 11010802027423号