当前位置:
X-MOL 学术
›
J. Chem. Theory Comput.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Data-Driven Approaches Can Overcome the Cost-Accuracy Trade-Off in Multireference Diagnostics.
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2020-06-14 , DOI: 10.1021/acs.jctc.0c00358 Chenru Duan 1, 2 , Fang Liu 1 , Aditya Nandy 1, 2 , Heather J Kulik 1
Journal of Chemical Theory and Computation ( IF 5.7 ) Pub Date : 2020-06-14 , DOI: 10.1021/acs.jctc.0c00358 Chenru Duan 1, 2 , Fang Liu 1 , Aditya Nandy 1, 2 , Heather J Kulik 1
Affiliation
|
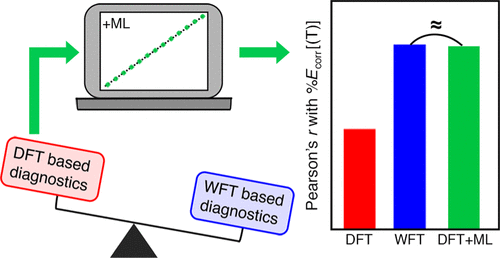
High-throughput computational screening typically employs methods (i.e., density functional theory or DFT) that can fail to describe challenging molecules, such as those with strongly correlated electronic structure. In such cases, multireference (MR) correlated wavefunction theory (WFT) would be the appropriate choice but remains more challenging to carry out and automate than single-reference (SR) WFT or DFT. Numerous diagnostics have been proposed for identifying when MR character is likely to have an effect on the predictive power of SR calculations, but conflicting conclusions about diagnostic performance have been reached on small data sets. We compute 15 MR diagnostics, ranging from affordable DFT-based to more costly MR-WFT-based diagnostics, on a set of 3165 equilibrium and distorted small organic molecules containing up to six heavy atoms. Conflicting MR character assignments and low pairwise linear correlations among diagnostics are also observed over this set. We evaluate the ability of existing diagnostics to predict the percent recovery of the correlation energy, %Ecorr. None of the DFT-based diagnostics are nearly as predictive of %Ecorr as the best WFT-based diagnostics. To overcome the limitation of this cost–accuracy trade-off, we develop machine learning (ML, i.e., kernel ridge regression) models to predict WFT-based diagnostics from a combination of DFT-based diagnostics and a new, size-independent 3D geometric representation. The ML-predicted diagnostics correlate as well with MR effects as their computed (i.e., with WFT) values, significantly improving over the DFT-based diagnostics on which the models were trained. These ML models thus provide a promising approach to improve upon DFT-based diagnostic accuracy while remaining suitably low cost for high-throughput screening.
中文翻译:

数据驱动的方法可以克服多参考诊断中的成本准确性折衷。
高通量计算筛选通常采用无法描述具有挑战性的分子(例如具有高度相关电子结构的分子)的方法(即密度泛函理论或DFT)。在这种情况下,多参考(MR)相关波函数理论(WFT)将是合适的选择,但与单参考(SR)WFT或DFT相比,执行和自动化仍然更具挑战性。已经提出了许多诊断方法来识别MR特性何时可能对SR计算的预测能力产生影响,但是在小数据集上却得出了有关诊断性能的矛盾结论。我们计算了15种MR诊断,从价格合理的DFT诊断到昂贵的MR-WFT诊断,在一组3165平衡和扭曲的有机小分子上包含多达六个重原子。MR字符分配冲突和诊断之间的低成对线性相关性也被观察到这一组。我们评估现有诊断程序预测相关能量回收百分比的能力,%E corr。基于DFT的诊断没有一个能比最好的基于WFT的诊断对%E corr的预测高。为了克服这种成本-准确性折衷的局限性,我们开发了机器学习(ML,即内核岭回归)模型,以结合基于DFT的诊断程序和新的尺寸无关的3D几何图形来预测基于WFT的诊断程序表示。ML预测的诊断值与其MR效果的计算值(即WFT)也相关,并且与训练模型的基于DFT的诊断值相比有显着改善。因此,这些ML模型提供了一种有前途的方法,可以改善基于DFT的诊断准确性,同时又能以适当的低成本保持高通量筛选。
更新日期:2020-07-14
中文翻译:
数据驱动的方法可以克服多参考诊断中的成本准确性折衷。
高通量计算筛选通常采用无法描述具有挑战性的分子(例如具有高度相关电子结构的分子)的方法(即密度泛函理论或DFT)。在这种情况下,多参考(MR)相关波函数理论(WFT)将是合适的选择,但与单参考(SR)WFT或DFT相比,执行和自动化仍然更具挑战性。已经提出了许多诊断方法来识别MR特性何时可能对SR计算的预测能力产生影响,但是在小数据集上却得出了有关诊断性能的矛盾结论。我们计算了15种MR诊断,从价格合理的DFT诊断到昂贵的MR-WFT诊断,在一组3165平衡和扭曲的有机小分子上包含多达六个重原子。MR字符分配冲突和诊断之间的低成对线性相关性也被观察到这一组。我们评估现有诊断程序预测相关能量回收百分比的能力,%E corr。基于DFT的诊断没有一个能比最好的基于WFT的诊断对%E corr的预测高。为了克服这种成本-准确性折衷的局限性,我们开发了机器学习(ML,即内核岭回归)模型,以结合基于DFT的诊断程序和新的尺寸无关的3D几何图形来预测基于WFT的诊断程序表示。ML预测的诊断值与其MR效果的计算值(即WFT)也相关,并且与训练模型的基于DFT的诊断值相比有显着改善。因此,这些ML模型提供了一种有前途的方法,可以改善基于DFT的诊断准确性,同时又能以适当的低成本保持高通量筛选。










































 京公网安备 11010802027423号
京公网安备 11010802027423号