当前位置:
X-MOL 学术
›
J. Softw. Evol. Process
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Selecting best predictors from large software repositories for highly accurate software effort estimation
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2020-06-09 , DOI: 10.1002/smr.2271 Sidra Tariq 1 , Muhammad Usman 1 , Alvis C.M. Fong 2
Journal of Software: Evolution and Process ( IF 1.7 ) Pub Date : 2020-06-09 , DOI: 10.1002/smr.2271 Sidra Tariq 1 , Muhammad Usman 1 , Alvis C.M. Fong 2
Affiliation
|
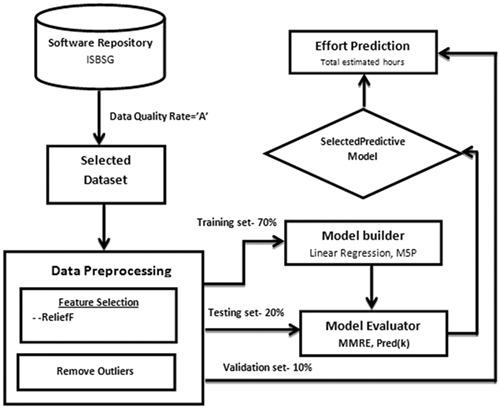
Accurate prediction of software effort is important for planning, scheduling, and allocating resources. However, software effort estimation has been a challenging task. Although numerous estimation models have been proposed, few achieve anything close to accurate prediction of software development effort. To achieve optimal results, machine learning techniques have recently been employed for predicting software development effort using relatively large software repositories. However, some issues remain unresolved, and this paper aims to address the following issues. First, feature selection methods often neglected the information rich variables present in the dataset. Second, selection of important features was done through statistical methods, which lack domain knowledge. Third, missing values in the data that significantly influence the prediction outcome was not efficiently handled. Fourth, majority of the literature neglected advanced evaluation measures, which thoroughly evaluate the ability of learning models to produce accurate results. To address the above issues, a machine learning‐based model has been proposed in this paper, which not only allows effective preprocessing of data but also provides highly accurate prediction results with minimum error rate. The purpose is to best identify attributes (predictors) from large software repositories that are most influential in the estimation of effort. In addition, we apply MMRE for better performance analysis.
中文翻译:

从大型软件存储库中选择最佳预测器以进行高度准确的软件工作量估算
准确预测软件工作量对于计划、调度和分配资源很重要。然而,软件工作量估算一直是一项具有挑战性的任务。尽管已经提出了许多估计模型,但很少有人能够准确预测软件开发工作量。为了获得最佳结果,最近使用机器学习技术来预测使用相对较大的软件存储库的软件开发工作。然而,一些问题仍未解决,本文旨在解决以下问题。首先,特征选择方法经常忽略数据集中存在的信息丰富的变量。其次,重要特征的选择是通过统计方法完成的,缺乏领域知识。第三,数据中显着影响预测结果的缺失值没有得到有效处理。第四,大多数文献忽视了高级评估措施,这些措施彻底评估了学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。彻底评估学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。彻底评估学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。
更新日期:2020-06-09
中文翻译:
从大型软件存储库中选择最佳预测器以进行高度准确的软件工作量估算
准确预测软件工作量对于计划、调度和分配资源很重要。然而,软件工作量估算一直是一项具有挑战性的任务。尽管已经提出了许多估计模型,但很少有人能够准确预测软件开发工作量。为了获得最佳结果,最近使用机器学习技术来预测使用相对较大的软件存储库的软件开发工作。然而,一些问题仍未解决,本文旨在解决以下问题。首先,特征选择方法经常忽略数据集中存在的信息丰富的变量。其次,重要特征的选择是通过统计方法完成的,缺乏领域知识。第三,数据中显着影响预测结果的缺失值没有得到有效处理。第四,大多数文献忽视了高级评估措施,这些措施彻底评估了学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。彻底评估学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。彻底评估学习模型产生准确结果的能力。为了解决上述问题,本文提出了一种基于机器学习的模型,该模型不仅可以对数据进行有效的预处理,还可以以最小的错误率提供高度准确的预测结果。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。目的是从大型软件存储库中最好地识别对工作量估计影响最大的属性(预测器)。此外,我们应用 MMRE 进行更好的性能分析。






































 京公网安备 11010802027423号
京公网安备 11010802027423号