Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-06-05 , DOI: 10.1016/j.jbi.2020.103465 Zhaozhao Xu 1 , Derong Shen 1 , Tiezheng Nie 1 , Yue Kou 1
|
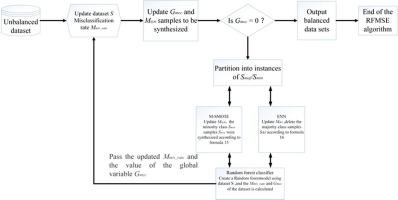
The problem of imbalanced data classification often exists in medical diagnosis. Traditional classification algorithms usually assume that the number of samples in each category is similar and their misclassification cost during training is equal. However, the misclassification cost of patient samples is higher than that of healthy person samples. Therefore, how to increase the identification of patients without affecting the classification of healthy individuals is an urgent problem. In order to solve the problem of imbalanced data classification in medical diagnosis, we propose a hybrid sampling algorithm called RFMSE, which combines the Misclassification-oriented Synthetic Minority Over-sampling TEchnique (M-SMOTE) and Edited Nearest Neighbor (ENN) based on Random Forest (RF). The algorithm is mainly composed of three parts. First, M-SMOTE is used to increase the number of samples in the minority class, while the over-sampling ratio of M-SMOTE is the misclassification of RF. Then, ENN is used to remove the noise ones from the majority samples. Finally, RF is used to perform classification prediction for the samples after hybrid sampling, and the stopping criterion for iterations is determined according to the changes of the classification index (i.e. Matthews Correlation Coefficient (MCC)). When the value of MCC continuously drops, the process of iterations will be stopped. Extensive experiments conducted on ten UCI datasets demonstrate that RFMSE can effectively solve the problem of imbalanced data classification. Compared with traditional methods, our method can improve F-value and MCC more effectively.
中文翻译:
基于随机森林的M-SMOTE和ENN混合采样算法,用于医学不平衡数据。
数据分类不平衡的问题通常存在于医学诊断中。传统的分类算法通常假设每个类别中的样本数量是相似的,并且在训练期间它们的错误分类成本是相等的。但是,患者样品的误分类成本高于健康人样品的误分类成本。因此,如何在不影响健康个体分类的前提下增加对患者的识别是当务之急。为了解决医学诊断中数据分类不平衡的问题,我们提出了一种混合采样算法RFMSE,该算法结合了面向分类错误的综合少数群体过采样技术(M-SMOTE)和基于随机的可编辑最近邻(ENN)。森林(RF)。该算法主要由三部分组成。第一,M-SMOTE用于增加少数派样本的数量,而M-SMOTE的过采样率则是RF的错误分类。然后,使用ENN去除大多数样本中的噪声。最后,利用RF对混合采样后的样本进行分类预测,并根据分类指标的变化(即Matthews相关系数(MCC))确定迭代的停止准则。当MCC的值连续下降时,迭代过程将停止。在十个UCI数据集上进行的大量实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。M-SMOTE的过采样率是RF的错误分类。然后,使用ENN去除大多数样本中的噪声。最后,利用RF对混合采样后的样本进行分类预测,并根据分类指标的变化(即Matthews相关系数(MCC))确定迭代的停止准则。当MCC的值连续下降时,迭代过程将停止。在十个UCI数据集上进行的大量实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。M-SMOTE的过采样率是RF的错误分类。然后,使用ENN去除大多数样本中的噪声。最后,利用RF对混合采样后的样本进行分类预测,并根据分类指标的变化(即Matthews相关系数(MCC))确定迭代的停止准则。当MCC的值连续下降时,迭代过程将停止。在十个UCI数据集上进行的广泛实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。RF用于对混合采样后的样本进行分类预测,并根据分类索引(即Matthews相关系数(MCC))的变化确定迭代的停止标准。当MCC的值连续下降时,迭代过程将停止。在十个UCI数据集上进行的大量实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。RF用于对混合采样后的样本进行分类预测,并根据分类索引(即Matthews相关系数(MCC))的变化确定迭代的停止标准。当MCC的值连续下降时,迭代过程将停止。在十个UCI数据集上进行的广泛实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。迭代过程将停止。在十个UCI数据集上进行的大量实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。迭代过程将停止。在十个UCI数据集上进行的大量实验表明,RFMSE可以有效解决数据分类不平衡的问题。与传统方法相比,我们的方法可以更有效地改善F值和MCC。










































 京公网安备 11010802027423号
京公网安备 11010802027423号