当前位置:
X-MOL 学术
›
Comput. Electr. Eng.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Segmentation-free writer identification based on convolutional neural network
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-07-01 , DOI: 10.1016/j.compeleceng.2020.106707 Parveen Kumar , Ambalika Sharma
Computers & Electrical Engineering ( IF 4.0 ) Pub Date : 2020-07-01 , DOI: 10.1016/j.compeleceng.2020.106707 Parveen Kumar , Ambalika Sharma
|
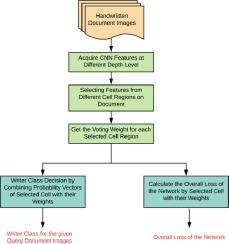
Abstract Handwriting recognition is one of the desired aspects of document understanding and analysis. It deals with the writing style of the document and learns the features which differentiate the writers. In this paper, a SEGmentation-free Writer Identification (SEG-WI) model is proposed based on a convolution neural network and a weakly supervised region selection mechanism. The model, SEG-WI, takes an unsegmented text document and produces the writer-ID with the region probability map. The probability vectors at each cell location in the input document constitute a region probability map. To achieve the best performance, top 10% to 50% cell regions are selected for decision making and a voting mechanism among the selected regions is used to identify the writer. The region selection, voting mechanism for decision making, and loss calculation are the main contributions in this work, which enables the proposed system as segmentation free. The proposed model is evaluated on different datasets such as IAM handwriting database (IAM), and computer vision lab (CVL) for English, Institut of communications technology/Ecole Nationale d’Ing nieurs de Tunis (IFN/ENIT) for Arabic, Kannada, and Devanagari for Indic, and outperforms compare with the state-of-the-art results. Moreover, a comparative analysis of the proposed model with and without region selection is performed to validate the effect of the region selection mechanism and it improves the performance of the model.
中文翻译:

基于卷积神经网络的无分割作者识别
摘要 手写识别是文档理解和分析的理想方面之一。它处理文档的写作风格并学习区分作者的特征。在本文中,提出了一种基于卷积神经网络和弱监督区域选择机制的 SEGmentation-free Writer Identification (SEG-WI) 模型。该模型 SEG-WI 采用未分段的文本文档,并使用区域概率图生成作者 ID。输入文档中每个单元格位置的概率向量构成区域概率图。为了获得最佳性能,选择前 10% 到 50% 的单元格区域进行决策,并使用所选区域之间的投票机制来识别作者。区域选择,决策投票机制,和损失计算是这项工作的主要贡献,这使所提出的系统成为无分割的。所提出的模型在不同的数据集上进行评估,例如 IAM 手写数据库 (IAM) 和英语计算机视觉实验室 (CVL)、通信技术学院/突尼斯国立大学 (IFN/ENIT) 阿拉伯语、卡纳达语、和梵文的印度语,并且与最先进的结果相比表现更好。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。和计算机视觉实验室 (CVL) 的英语,通信技术学院/突尼斯国立大学 (IFN/ENIT) 的阿拉伯语、卡纳达语和梵文的印度语,与最先进的技术相比表现出色结果。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。和计算机视觉实验室 (CVL) 的英语,通信技术学院/突尼斯国立大学 (IFN/ENIT) 的阿拉伯语、卡纳达语和梵文的印度语,与最先进的技术相比表现出色结果。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。
更新日期:2020-07-01
中文翻译:
基于卷积神经网络的无分割作者识别
摘要 手写识别是文档理解和分析的理想方面之一。它处理文档的写作风格并学习区分作者的特征。在本文中,提出了一种基于卷积神经网络和弱监督区域选择机制的 SEGmentation-free Writer Identification (SEG-WI) 模型。该模型 SEG-WI 采用未分段的文本文档,并使用区域概率图生成作者 ID。输入文档中每个单元格位置的概率向量构成区域概率图。为了获得最佳性能,选择前 10% 到 50% 的单元格区域进行决策,并使用所选区域之间的投票机制来识别作者。区域选择,决策投票机制,和损失计算是这项工作的主要贡献,这使所提出的系统成为无分割的。所提出的模型在不同的数据集上进行评估,例如 IAM 手写数据库 (IAM) 和英语计算机视觉实验室 (CVL)、通信技术学院/突尼斯国立大学 (IFN/ENIT) 阿拉伯语、卡纳达语、和梵文的印度语,并且与最先进的结果相比表现更好。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。和计算机视觉实验室 (CVL) 的英语,通信技术学院/突尼斯国立大学 (IFN/ENIT) 的阿拉伯语、卡纳达语和梵文的印度语,与最先进的技术相比表现出色结果。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。和计算机视觉实验室 (CVL) 的英语,通信技术学院/突尼斯国立大学 (IFN/ENIT) 的阿拉伯语、卡纳达语和梵文的印度语,与最先进的技术相比表现出色结果。此外,对有和没有区域选择的所提出模型进行了比较分析,以验证区域选择机制的效果,并提高了模型的性能。








































 京公网安备 11010802027423号
京公网安备 11010802027423号