当前位置:
X-MOL 学术
›
Comput. Graph.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Adversarial gesture generation with realistic gesture phasing
Computers & Graphics ( IF 2.5 ) Pub Date : 2020-06-01 , DOI: 10.1016/j.cag.2020.04.007 Ylva Ferstl , Michael Neff , Rachel McDonnell
Computers & Graphics ( IF 2.5 ) Pub Date : 2020-06-01 , DOI: 10.1016/j.cag.2020.04.007 Ylva Ferstl , Michael Neff , Rachel McDonnell
|
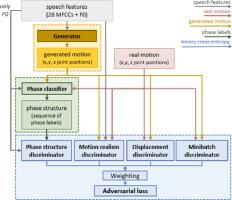
Abstract Conversational virtual agents are increasingly common and popular, but modeling their non-verbal behavior is a complex problem that remains unsolved. Gesture is a key component of speech-accompanying behavior but is difficult to model due to its non-deterministic and variable nature. We explore the use of a generative adversarial training paradigm to map speech to 3D gesture motion. We define the gesture generation problem as a series of smaller sub-problems, including plausible gesture dynamics, realistic joint configurations, and diverse and smooth motion. Each sub-problem is monitored by separate adversaries. For the problem of enforcing realistic gesture dynamics in our output, we train three classifiers with different levels of detail to automatically detect gesture phases. We hand-annotate and evaluate over 3.8 hours of gesture data for this purpose, including samples of a second speaker for comparing and validating our results. We find adversarial training to be superior to the use of a standard regression loss and discuss the benefit of each of our training objectives. We recorded a dataset of over 6 hours of natural, unrehearsed speech with high-quality motion capture, as well as audio and video recording.
中文翻译:

具有逼真手势相位的对抗性手势生成
摘要 会话虚拟代理越来越普遍和流行,但对其非语言行为建模是一个尚未解决的复杂问题。手势是语音伴随行为的关键组成部分,但由于其非确定性和可变性而难以建模。我们探索使用生成对抗训练范式将语音映射到 3D 手势运动。我们将手势生成问题定义为一系列较小的子问题,包括合理的手势动态、逼真的关节配置以及多样化和平滑的运动。每个子问题都由不同的对手监控。对于在我们的输出中强制执行逼真的手势动态的问题,我们训练了三个具有不同细节级别的分类器来自动检测手势阶段。我们手工注释和评估超过 3。用于此目的的 8 小时手势数据,包括用于比较和验证我们的结果的第二个扬声器的样本。我们发现对抗性训练优于使用标准回归损失,并讨论了我们每个训练目标的好处。我们使用高质量的动作捕捉以及音频和视频录制了超过 6 小时的自然、未经排练的语音数据集。
更新日期:2020-06-01
中文翻译:
具有逼真手势相位的对抗性手势生成
摘要 会话虚拟代理越来越普遍和流行,但对其非语言行为建模是一个尚未解决的复杂问题。手势是语音伴随行为的关键组成部分,但由于其非确定性和可变性而难以建模。我们探索使用生成对抗训练范式将语音映射到 3D 手势运动。我们将手势生成问题定义为一系列较小的子问题,包括合理的手势动态、逼真的关节配置以及多样化和平滑的运动。每个子问题都由不同的对手监控。对于在我们的输出中强制执行逼真的手势动态的问题,我们训练了三个具有不同细节级别的分类器来自动检测手势阶段。我们手工注释和评估超过 3。用于此目的的 8 小时手势数据,包括用于比较和验证我们的结果的第二个扬声器的样本。我们发现对抗性训练优于使用标准回归损失,并讨论了我们每个训练目标的好处。我们使用高质量的动作捕捉以及音频和视频录制了超过 6 小时的自然、未经排练的语音数据集。









































 京公网安备 11010802027423号
京公网安备 11010802027423号