当前位置:
X-MOL 学术
›
Appl. Acoust.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Deep neural networks based binary classification for single channel speaker independent multi-talker speech separation
Applied Acoustics ( IF 3.4 ) Pub Date : 2020-10-01 , DOI: 10.1016/j.apacoust.2020.107385 Nasir Saleem , Muhammad Irfan Khattak
Applied Acoustics ( IF 3.4 ) Pub Date : 2020-10-01 , DOI: 10.1016/j.apacoust.2020.107385 Nasir Saleem , Muhammad Irfan Khattak
|
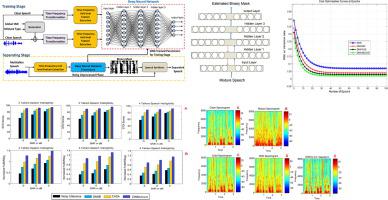
Abstract Speech separation is an important task of separating a target speech from the mixture signals. Speaker-independent multi-talker speech separation is a challenging task due to unpredictability of the target and interfering speech in the target-interference mixtures. Conventionally, speech separation is used as a signal processing problem, but recently it is formulated as a deep learning problem and discriminative patterns of the speech are learned from the training data. In this paper, we consider the ideal binary mask (IBM) as a supervised binary classification training-target by using fully connected deep neural networks (DNN) for single-channel speaker-independent multi-talker speech separation. The train DNNs is used to estimate IBM training-target. The mean square error (MSE) is used as an objective cost function. Standard backpropagation and Monte-Carlo dropout regularization approaches are used for better generalization and overfitting during training. The estimated training-target is applied to the mixtures to obtain the separated target speech. We have addressed the over-smoothing problem and performed equalization of spectral variances to match the estimated and clean speech features. Our experimental results in various evaluating conditions report that the proposed method outperformed the competing methods in terms of the Perceptual Evaluation of Speech Quality (PESQ), Segmental SNR (SNRSeg), Short-time objective intelligibility (STOI), normalized Frequency weighted SNRSeg (nFwSNRSeg) and HIT-FA rates.
中文翻译:

基于深度神经网络的单通道说话人独立多说话人语音分离的二元分类
摘要 语音分离是从混合信号中分离目标语音的一项重要任务。由于目标的不可预测性和目标干扰混合中的干扰语音,独立于说话者的多说话者语音分离是一项具有挑战性的任务。传统上,语音分离被用作信号处理问题,但最近它被表述为深度学习问题,并从训练数据中学习语音的判别模式。在本文中,我们通过使用完全连接的深度神经网络 (DNN) 进行单通道独立于多说话者的语音分离,将理想二元掩码 (IBM) 视为有监督的二元分类训练目标。训练 DNN 用于估计 IBM 训练目标。均方误差 (MSE) 用作目标成本函数。标准反向传播和 Monte-Carlo dropout 正则化方法用于在训练期间更好地泛化和过度拟合。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。
更新日期:2020-10-01
中文翻译:
基于深度神经网络的单通道说话人独立多说话人语音分离的二元分类
摘要 语音分离是从混合信号中分离目标语音的一项重要任务。由于目标的不可预测性和目标干扰混合中的干扰语音,独立于说话者的多说话者语音分离是一项具有挑战性的任务。传统上,语音分离被用作信号处理问题,但最近它被表述为深度学习问题,并从训练数据中学习语音的判别模式。在本文中,我们通过使用完全连接的深度神经网络 (DNN) 进行单通道独立于多说话者的语音分离,将理想二元掩码 (IBM) 视为有监督的二元分类训练目标。训练 DNN 用于估计 IBM 训练目标。均方误差 (MSE) 用作目标成本函数。标准反向传播和 Monte-Carlo dropout 正则化方法用于在训练期间更好地泛化和过度拟合。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。将估计的训练目标应用于混合以获得分离的目标语音。我们已经解决了过度平滑问题并执行了频谱方差均衡以匹配估计的和干净的语音特征。我们在各种评估条件下的实验结果表明,所提出的方法在语音质量感知评估 (PESQ)、分段 SNR (SNRSeg)、短时客观可懂度 (STOI)、归一化频率加权 SNRSeg (nFwSNRSeg) 方面优于竞争方法) 和 HIT-FA 率。










































 京公网安备 11010802027423号
京公网安备 11010802027423号