JACC: Heart Failure ( IF 13.0 ) Pub Date : 2020-05-06 , DOI: 10.1016/j.jchf.2020.01.012 Linyuan Jing 1 , Alvaro E Ulloa Cerna 1 , Christopher W Good 2 , Nathan M Sauers 3 , Gargi Schneider 4 , Dustin N Hartzel 5 , Joseph B Leader 5 , H Lester Kirchner 6 , Yirui Hu 6 , David M Riviello 7 , Joshua V Stough 8 , Seth Gazes 3 , Allyson Haggerty 1 , Sushravya Raghunath 1 , Brendan J Carry 2 , Christopher M Haggerty 9 , Brandon K Fornwalt 10
|
Background
Heart failure is a prevalent, costly disease for which new value-based payment models demand optimized population management strategies.
Objectives
This study sought to generate a strategy for managing populations of patients with heart failure by leveraging large clinical datasets and machine learning.
Methods
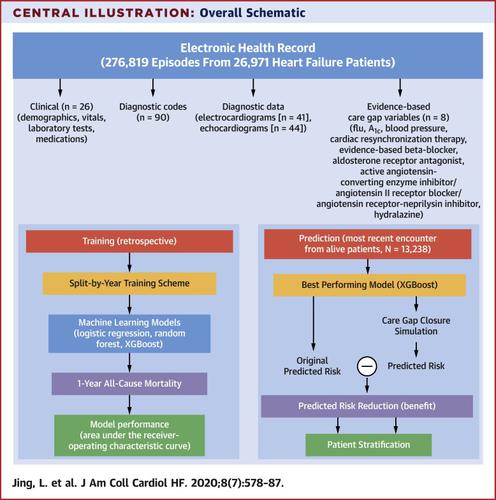
Geisinger electronic health record data were used to train machine learning models to predict 1-year all-cause mortality in 26,971 patients with heart failure who underwent 276,819 clinical episodes. There were 26 clinical variables (demographics, laboratory test results, medications), 90 diagnostic codes, 41 electrocardiogram measurements and patterns, 44 echocardiographic measurements, and 8 evidence-based “care gaps”: flu vaccine, blood pressure of <130/80 mm Hg, A1c of <8%, cardiac resynchronization therapy, and active medications (active angiotensin-converting enzyme inhibitor/angiotensin II receptor blocker/angiotensin receptor-neprilysin inhibitor, aldosterone receptor antagonist, hydralazine, and evidence-based beta-blocker) were collected. Care gaps represented actionable variables for which associations with all-cause mortality were modeled from retrospective data and then used to predict the benefit of prospective interventions in 13,238 currently living patients.
Results
Machine learning models achieved areas under the receiver-operating characteristic curve (AUCs) of 0.74 to 0.77 in a split-by-year training/test scheme, with the nonlinear XGBoost model (AUC: 0.77) outperforming linear logistic regression (AUC: 0.74). Out of 13,238 currently living patients, 2,844 were predicted to die within a year, and closing all care gaps was predicted to save 231 of these lives. Prioritizing patients for intervention by using the predicted reduction in 1-year mortality risk outperformed all other priority rankings (e.g., random selection or Seattle Heart Failure risk score).
Conclusions
Machine learning can be used to priority-rank patients most likely to benefit from interventions to optimize evidence-based therapies. This approach may prove useful for optimizing heart failure population health management teams within value-based payment models.
中文翻译:
一种用于心力衰竭人群管理的机器学习方法。
背景
心力衰竭是一种流行的,代价高昂的疾病,为此,新的基于价值的支付模型需要优化的人口管理策略。
目标
这项研究试图通过利用大型临床数据集和机器学习来产生一种管理心力衰竭患者人群的策略。
方法
Geisinger电子健康记录数据用于训练机器学习模型,以预测26,971例心力衰竭患者的1年全因死亡率,这些患者经历了276,819次临床发作。有26种临床变量(人口统计学,实验室检查结果,药物),90种诊断代码,41种心电图测量和模式,44种超声心动图测量以及8种基于证据的“护理差距”:流感疫苗,血压<130/80 mm汞,A 1c在<8%的患者中,收集了心脏再同步治疗和活性药物(活性血管紧张素转换酶抑制剂/血管紧张素II受体阻滞剂/血管紧张素受体-中性溶酶抑制剂,醛固酮受体拮抗剂,肼苯哒嗪和循证β受体阻滞剂)。护理差距代表了可操作的变量,可通过回顾性数据对与全因死亡率相关的模型进行建模,然后将其用于预测13238名目前存活患者的前瞻性干预措施的获益。
结果
机器学习模型在按年划分的训练/测试方案中实现了接收者操作特征曲线(AUC)处于0.74至0.77的区域,而非线性XGBoost模型(AUC:0.77)的表现优于线性逻辑回归(AUC:0.74) 。在目前居住的13238名患者中,有2844名预计在一年内死亡,填补所有医疗缺口预计将挽救其中231条生命。通过使用预测的1年死亡率风险降低来优先考虑进行干预的患者优于所有其他优先级排名(例如,随机选择或Seattle Heart Failure风险评分)。
结论
机器学习可用于对最可能受益于干预以优化循证疗法的患者进行优先级排序。这种方法对于在基于价值的支付模型中优化心力衰竭人群健康管理团队可能很有用。


























 京公网安备 11010802027423号
京公网安备 11010802027423号