当前位置:
X-MOL 学术
›
J. Biomed. Inform.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Neural negated entity recognition in Spanish electronic health records.
Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-04-13 , DOI: 10.1016/j.jbi.2020.103419 Sara Santiso 1 , Alicia Pérez 1 , Arantza Casillas 1 , Maite Oronoz 1
Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-04-13 , DOI: 10.1016/j.jbi.2020.103419 Sara Santiso 1 , Alicia Pérez 1 , Arantza Casillas 1 , Maite Oronoz 1
Affiliation
|
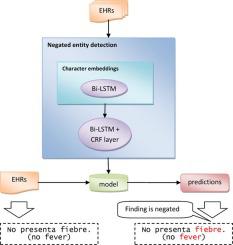
This work deals with negation detection in the context of clinical texts. Negation detection is a key for decision support systems since negated events (detection of absence of some events) help ascertain current medical conditions. For artificial intelligence, negation detection is a valuable point as it can revert the meaning of a part of a text and, accordingly, influence other tasks such as medical dosage adjustment, the detection of adverse drug reactions or hospital acquired diseases. We focus on negated medical events such as disorders, findings and allergies. From Natural Language Processing (NLP) background, we refer to them as negated medical entities. A novelty of this work is that we approached this task as Named Entity Recognition (NER) with the restriction that just negated medical entities must be recognized (in an attempt to help distinguish them from non-negated ones). Our study is driven with Electronic Health Records (EHRs) written in Spanish. A challenge to cope with is the lexical variability (alternative medical forms, abbreviations, etc.). To this end, we employed an approach based on deep learning. Specifically, the system combines character embeddings to cope with out-of-vocabulary (OOV) words, Long Short-Term Memory (LSTM) networks to model contextual representations and it makes use of Conditional Random Fields (CRF) to classify each medical entity as either negated or not given the contextual dense representation. Moreover, we explored both embeddings created from words and embeddings created from lemmas. The best results were obtained with the lemmatized embeddings. Apparently, this approach reinforced the capability of the LSTMs to cope with the high lexical variability. The f-measure for exact-match was 65.1 and 82.4 for the partial-match.
中文翻译:

西班牙电子健康记录中的神经否定实体识别。
这项工作涉及临床文本上下文中的否定检测。否定检测是决策支持系统的关键,因为否定事件(检测到某些事件不存在)有助于确定当前的医疗状况。对于人工智能而言,否定检测是很有价值的一点,因为它可以还原部分文本的含义,并因此影响其他任务,例如医疗剂量调整,药物不良反应的检测或医院获得性疾病的检测。我们专注于负面的医疗事件,例如疾病,发现和过敏。从自然语言处理(NLP)的背景来看,我们将它们称为否定医学实体。这项工作的新颖之处在于,我们以命名实体识别(NER)的身份来完成这项任务,其限制是必须识别刚刚被否定的医疗实体(以试图将它们与非被否定的医疗实体区分开)。我们的研究是用西班牙语编写的电子健康记录(EHR)驱动的。要应对的挑战是词汇变异性(替代医学形式,缩写等)。为此,我们采用了基于深度学习的方法。具体来说,该系统结合了字符嵌入以应对语音不佳(OOV)单词,长短期记忆(LSTM)网络来建模上下文表示,并且利用条件随机字段(CRF)将每个医疗实体分类为否定或未给出上下文密集表示。此外,我们探索了从单词创建的嵌入和从引理创建的嵌入。使用去势化嵌入获得最佳结果。显然,这种方法增强了LSTM应对高词汇变异性的能力。完全匹配的f测度为部分匹配的65.1和82.4。
更新日期:2020-04-21
中文翻译:
西班牙电子健康记录中的神经否定实体识别。
这项工作涉及临床文本上下文中的否定检测。否定检测是决策支持系统的关键,因为否定事件(检测到某些事件不存在)有助于确定当前的医疗状况。对于人工智能而言,否定检测是很有价值的一点,因为它可以还原部分文本的含义,并因此影响其他任务,例如医疗剂量调整,药物不良反应的检测或医院获得性疾病的检测。我们专注于负面的医疗事件,例如疾病,发现和过敏。从自然语言处理(NLP)的背景来看,我们将它们称为否定医学实体。这项工作的新颖之处在于,我们以命名实体识别(NER)的身份来完成这项任务,其限制是必须识别刚刚被否定的医疗实体(以试图将它们与非被否定的医疗实体区分开)。我们的研究是用西班牙语编写的电子健康记录(EHR)驱动的。要应对的挑战是词汇变异性(替代医学形式,缩写等)。为此,我们采用了基于深度学习的方法。具体来说,该系统结合了字符嵌入以应对语音不佳(OOV)单词,长短期记忆(LSTM)网络来建模上下文表示,并且利用条件随机字段(CRF)将每个医疗实体分类为否定或未给出上下文密集表示。此外,我们探索了从单词创建的嵌入和从引理创建的嵌入。使用去势化嵌入获得最佳结果。显然,这种方法增强了LSTM应对高词汇变异性的能力。完全匹配的f测度为部分匹配的65.1和82.4。








































 京公网安备 11010802027423号
京公网安备 11010802027423号