当前位置:
X-MOL 学术
›
Adv. Theory Simul.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Multi‐Layer Feature Selection Incorporating Weighted Score‐Based Expert Knowledge toward Modeling Materials with Targeted Properties
Advanced Theory and Simulations ( IF 2.9 ) Pub Date : 2020-01-15 , DOI: 10.1002/adts.201900215 Yue Liu 1 , Jun‐Ming Wu 1 , Maxim Avdeev 2, 3 , Si‐Qi Shi 4
Advanced Theory and Simulations ( IF 2.9 ) Pub Date : 2020-01-15 , DOI: 10.1002/adts.201900215 Yue Liu 1 , Jun‐Ming Wu 1 , Maxim Avdeev 2, 3 , Si‐Qi Shi 4
Affiliation
|
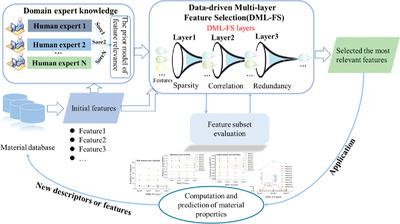
Selecting proper descriptors or features is one of the central problems in exploring structure–activity relationships of materials using machine learning models. The current feature selection algorithms usually require tedious hyperparameter tuning and do not actively consider the prior knowledge of domain experts about the features. Here, this work proposes a data‐driven multi‐layer feature selection method incorporating domain expert knowledge named DML‐FSdek, which is automated, with users entering training data without manual tuning of the hyperparameters. The domain expert knowledge is quantified by means of weighted scoring and integrated into the selection process to eliminate the risk of crucial features being removed. The test studies on ten material properties datasets demonstrate the potential of the approach to automatically search for a reduced feature set with lower root mean square errors than those for the initial feature set. Essentially, the most relevant material features, the number of which is much smaller than that in the original feature set, are automatically selected to establish a closer and more accurate structure–activity relationship for the materials of interest. As a result, the method represents the targeted properties of materials with a smaller and more interpretable set of features while ensuring equal or better prediction accuracy.
中文翻译:

结合基于加权分数的专家知识的多层特征选择,可对具有目标特性的材料进行建模
选择合适的描述符或特征是使用机器学习模型探索材料的结构-活性关系的中心问题之一。当前的特征选择算法通常需要繁琐的超参数调整,并且不会积极考虑领域专家关于特征的先验知识。在这里,这项工作提出了一种数据驱动的多层特征选择方法,该方法结合了名为DML-FS dek的领域专家知识,这是自动的,用户无需手动调整超参数即可输入训练数据。领域专家知识通过加权计分进行量化,并集成到选择过程中,以消除关键特征被删除的风险。对十个材料特性数据集的测试研究表明,该方法具有潜在的潜力,可以自动搜索比均方根误差小的均方根误差的简化特征集。本质上,最相关的材料特征(其数量比原始特征集中的数量要少得多)会自动选择,以为感兴趣的材料建立更紧密,更准确的结构-活性关系。结果是,
更新日期:2020-03-04
中文翻译:
结合基于加权分数的专家知识的多层特征选择,可对具有目标特性的材料进行建模
选择合适的描述符或特征是使用机器学习模型探索材料的结构-活性关系的中心问题之一。当前的特征选择算法通常需要繁琐的超参数调整,并且不会积极考虑领域专家关于特征的先验知识。在这里,这项工作提出了一种数据驱动的多层特征选择方法,该方法结合了名为DML-FS dek的领域专家知识,这是自动的,用户无需手动调整超参数即可输入训练数据。领域专家知识通过加权计分进行量化,并集成到选择过程中,以消除关键特征被删除的风险。对十个材料特性数据集的测试研究表明,该方法具有潜在的潜力,可以自动搜索比均方根误差小的均方根误差的简化特征集。本质上,最相关的材料特征(其数量比原始特征集中的数量要少得多)会自动选择,以为感兴趣的材料建立更紧密,更准确的结构-活性关系。结果是,










































 京公网安备 11010802027423号
京公网安备 11010802027423号