Digital Signal Processing ( IF 2.9 ) Pub Date : 2020-02-19 , DOI: 10.1016/j.dsp.2020.102697 Md Shohidul Islam , Yuanyuan Zhu , Md Imran Hossain , Rizwan Ullah , Zhongfu Ye
|
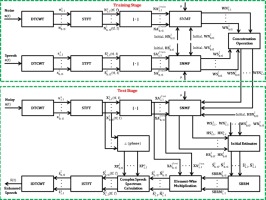
In this paper, we propose a novel single-channel speech enhancement algorithm that applies dual-domain transforms comprising of dual-tree complex wavelet transform (DTCWT) and short-time Fourier transform (STFT) with a sparse non-negative matrix factorization (SNMF). The first domain belongs to the DTCWT, which is utilized on the time domain signals to conquer the weakness of signal distortions brought about by the downsampling of the discrete wavelet packet transform (DWPT) and delivered a set of subband signals. The second domain alludes to the STFT, which is exploited to each subband signal and built a complex spectrogram. At last, we apply the SNMF to the magnitude spectrogram for extracting speech components. In short, the DTCWT decomposes the time-domain noisy signal into a set of subband signals and afterward applied STFT to each subband signal, and we get nonnegative matrices by taking the absolute value of the complex matrix. From this point forward, we apply SNMF to each nonnegative matrix and identify the speech components. Finally, the estimated signal can be achieved through a subband binary ratio mask (SBRM) by applying the inverse STFT (ISTFT) and, subsequently, the inverse DTCWT (IDTCWT). The proposed approach is assessed utilizing the GRID audio-visual and IEEE databases, and diverse kinds of noises such as stationary, non-stationary, and quasi-stationary. The exploratory outcomes demonstrate that the proposed algorithm improved objective speech quality and intelligibility altogether at all considered signal to noise ratios (SNRs), compared to the other seven speech enhancement methods of STFT-SNMF, STFT-SNMFSE, MLD-STFT-SNMF, STFT-GDL, STFT-CJSR, DTCWT-SNMF, and DWPT-STFT-SNMF.
中文翻译:
使用稀疏非负矩阵分解的有监督单通道双域语音增强
在本文中,我们提出了一种新颖的单通道语音增强算法,该算法将双域变换(包括双树复数小波变换(DTCWT)和短时傅立叶变换(STFT))与稀疏非负矩阵分解(SNMF)应用)。第一个域属于DTCWT,它在时域信号上被用来克服离散小波包变换(DWPT)的下采样所带来的信号失真的弱点,并传递了一组子带信号。第二个域涉及STFT,它被用于每个子带信号并建立了一个复杂的频谱图。最后,我们将SNMF应用于幅度谱图以提取语音成分。简而言之,DTCWT将时域噪声信号分解为一组子带信号,然后将STFT应用于每个子带信号,我们通过获取复矩阵的绝对值来获得非负矩阵。从这一点出发,我们将SNMF应用于每个非负矩阵,并识别语音成分。最后,可以通过应用反STFT(ISTFT)和随后应用反DTCWT(IDTCWT)的子带二进制比率掩码(SBRM)来获得估计的信号。利用GRID视听和IEEE数据库以及各种噪声(例如平稳,非平稳和准平稳)对所提出的方法进行了评估。探索性结果表明,所提出的算法在所有考虑的信噪比(SNR)方面均改善了目标语音质量和清晰度,










































 京公网安备 11010802027423号
京公网安备 11010802027423号