当前位置:
X-MOL 学术
›
Atmos. Environ.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Spatial modelling of particulate matter air pollution sensor measurements collected by community scientists while cycling, land use regression with spatial cross-validation, and applications of machine learning for data correction
Atmospheric Environment ( IF 4.2 ) Pub Date : 2020-06-01 , DOI: 10.1016/j.atmosenv.2020.117479 Matthew D. Adams , Felix Massey , Karl Chastko , Calvin Cupini
Atmospheric Environment ( IF 4.2 ) Pub Date : 2020-06-01 , DOI: 10.1016/j.atmosenv.2020.117479 Matthew D. Adams , Felix Massey , Karl Chastko , Calvin Cupini
|
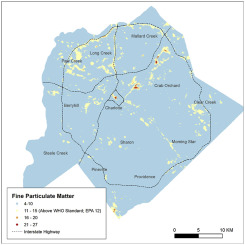
Abstract Fine particulate matter air pollution is a global issue; cycling is a global activity. In our paper, particulate matter less than 2.5 μm (PM2.5) air pollution data obtained by community scientists while cycling is used to develop high-resolution spatial air pollution maps. Mapping is completed using a land use regression model for Charlotte, North Carolina. The air pollution observations were obtained with a low-cost sensor. We evaluated the accuracy of the sensor through a collocation study for 3203 h, which identified the sensor had a mean bias of 7.25 μg/m3 and a correlation of r = 0.77 with an US EPA Federal Equivalent Monitor. A machine learning model was developed to adjust the sensor observations, which demonstrated their highest errors during periods of high humidity. The adjustment was able to reduce the root mean squared error from 12 μg/m3 to 3.8 μg/m3, and the mean bias was reduced to −0.5 μg/m3. Cycling times were not balanced throughout the day nor the year. We applied a temporal adjustment algorithm to account for this imbalance in observation periods with the intention of producing long-term estimates representing the sampling period of 2016 and 2017. The long-term air pollution surface for the city was generated with a land use regression model. Both linear regression and machine learning approaches were applied. The linear regression model performed poorly with a training R2 of 0.15 and a cross-validation R2 of 0.15. A stacked ensemble model was developed using machine learning, which had a training 5-fold cross-validation mean residual deviance of 3.82 μg/m3, a root mean squared error of 1.95 μg/m3, and a mean absolute error of 0.95 μg/m3. Performance remained strong during cross-validation, which included both a random sample approach (RMSE = 1.52 μg/m3) and a spatial blocking cross-validation method (RMSE = 2.8 μg/m3).
中文翻译:

社区科学家在骑自行车时收集的颗粒物空气污染传感器测量值的空间建模、具有空间交叉验证的土地利用回归以及机器学习在数据校正中的应用
摘要 细颗粒物空气污染是一个全球性问题;骑自行车是一项全球性的活动。在我们的论文中,社区科学家在骑自行车时获得的小于 2.5 微米的颗粒物 (PM2.5) 空气污染数据用于开发高分辨率空间空气污染图。地图是使用北卡罗来纳州夏洛特的土地利用回归模型完成的。空气污染观测是通过低成本传感器获得的。我们通过 3203 小时的搭配研究评估了传感器的准确性,确定传感器的平均偏差为 7.25 μg/m3,与美国 EPA 联邦等效监测器的相关性 r = 0.77。开发了一种机器学习模型来调整传感器观察结果,这表明它们在高湿度期间的误差最大。调整能够将均方根误差从 12 μg/m3 降低到 3.8 μg/m3,平均偏差降低到 -0.5 μg/m3。全天或全年的骑行时间都不平衡。我们应用了时间调整算法来解释观察期的这种不平衡,目的是产生代表 2016 年和 2017 年采样期的长期估计。城市的长期空气污染表面是用土地利用回归模型生成的. 应用了线性回归和机器学习方法。线性回归模型表现不佳,训练 R2 为 0.15,交叉验证 R2 为 0.15。使用机器学习开发了堆叠集成模型,其训练 5 倍交叉验证平均残差偏差为 3.82 μg/m3,均方根误差为 1.95 μg/m3,平均绝对误差为 0.95 μg/m3。在交叉验证期间性能仍然强劲,其中包括随机样本方法 (RMSE = 1.52 μg/m3) 和空间阻塞交叉验证方法 (RMSE = 2.8 μg/m3)。
更新日期:2020-06-01
中文翻译:
社区科学家在骑自行车时收集的颗粒物空气污染传感器测量值的空间建模、具有空间交叉验证的土地利用回归以及机器学习在数据校正中的应用
摘要 细颗粒物空气污染是一个全球性问题;骑自行车是一项全球性的活动。在我们的论文中,社区科学家在骑自行车时获得的小于 2.5 微米的颗粒物 (PM2.5) 空气污染数据用于开发高分辨率空间空气污染图。地图是使用北卡罗来纳州夏洛特的土地利用回归模型完成的。空气污染观测是通过低成本传感器获得的。我们通过 3203 小时的搭配研究评估了传感器的准确性,确定传感器的平均偏差为 7.25 μg/m3,与美国 EPA 联邦等效监测器的相关性 r = 0.77。开发了一种机器学习模型来调整传感器观察结果,这表明它们在高湿度期间的误差最大。调整能够将均方根误差从 12 μg/m3 降低到 3.8 μg/m3,平均偏差降低到 -0.5 μg/m3。全天或全年的骑行时间都不平衡。我们应用了时间调整算法来解释观察期的这种不平衡,目的是产生代表 2016 年和 2017 年采样期的长期估计。城市的长期空气污染表面是用土地利用回归模型生成的. 应用了线性回归和机器学习方法。线性回归模型表现不佳,训练 R2 为 0.15,交叉验证 R2 为 0.15。使用机器学习开发了堆叠集成模型,其训练 5 倍交叉验证平均残差偏差为 3.82 μg/m3,均方根误差为 1.95 μg/m3,平均绝对误差为 0.95 μg/m3。在交叉验证期间性能仍然强劲,其中包括随机样本方法 (RMSE = 1.52 μg/m3) 和空间阻塞交叉验证方法 (RMSE = 2.8 μg/m3)。










































 京公网安备 11010802027423号
京公网安备 11010802027423号