Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Comparative analyses of error handling strategies for next-generation sequencing in precision medicine.
Scientific Reports ( IF 4.6 ) Pub Date : 2020-04-01 , DOI: 10.1038/s41598-020-62675-8 Hannah F Löchel 1 , Dominik Heider 1
Scientific Reports ( IF 4.6 ) Pub Date : 2020-04-01 , DOI: 10.1038/s41598-020-62675-8 Hannah F Löchel 1 , Dominik Heider 1
Affiliation
|
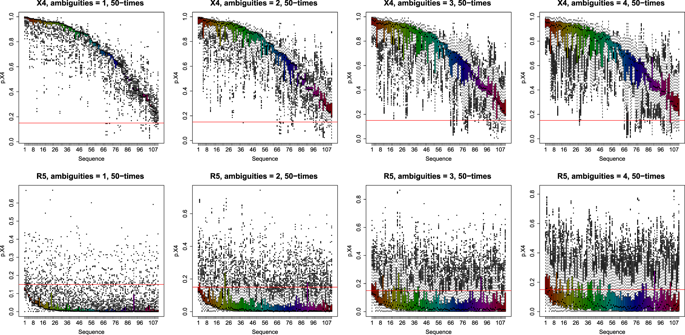
Next-generation sequencing (NGS) offers the opportunity to sequence millions and billions of DNA sequences in a short period, leading to novel applications in personalized medicine, such as cancer diagnostics or antiviral therapy. Nevertheless, sequencing technologies have different error rates, which occur during the sequencing process. If the NGS data is used for diagnostics, these sequences with errors are typically neglected or a worst-case scenario is assumed. In the current study, we focused on the impact of ambiguous bases on therapy recommendations for Human Immunodeficiency Virus 1 (HIV-1) patients. Concretely, we analyzed the treatment recommendation with entry blockers based on prediction models for co-receptor tropism. We compared three different error handling strategies that have been used in the literature, namely (i) neglection, (ii) worst-case assumption, and (iii) deconvolution with a majority vote. We could show that for two or more ambiguous positions per sequence a reliable prediction is generally no longer possible. Moreover, also the position of ambiguity plays a crucial role. Thus, we analyzed the error probability distributions of existing sequencing technologies, e.g., Illumina MiSeq or PacBio, with respect to the aforementioned error handling strategies and it turned out that neglection outperforms the other strategies in the case where no systematic errors are present. In other cases, the deconvolution strategy with the majority vote should be preferred.
中文翻译:

精密医学下一代测序错误处理策略的比较分析。
下一代测序(NGS)提供了在短时间内对数百万亿个DNA序列进行测序的机会,从而导致了个性化医学的新应用,例如癌症诊断或抗病毒治疗。但是,测序技术具有不同的错误率,错误率在测序过程中会发生。如果将NGS数据用于诊断,则通常会忽略这些带有错误的序列,或者假定是最坏的情况。在当前的研究中,我们重点研究了含糊不清的碱对人类免疫缺陷病毒1(HIV-1)患者的治疗建议的影响。具体来说,我们基于共受体向性预测模型对采用进入阻断剂的治疗建议进行了分析。我们比较了文献中使用的三种不同的错误处理策略,即(i)忽略,(ii)最坏的假设,以及(iii)以多数票进行反卷积。我们可以证明,对于每个序列两个或多个歧义位置,通常不再可能进行可靠的预测。此外,歧义的立场也起着至关重要的作用。因此,针对上述错误处理策略,我们分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在不存在系统错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。歧义的立场也起着至关重要的作用。因此,我们针对上述错误处理策略分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在没有系统性错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。歧义的立场也起着至关重要的作用。因此,我们针对上述错误处理策略分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在没有系统性错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。
更新日期:2020-04-01
中文翻译:
精密医学下一代测序错误处理策略的比较分析。
下一代测序(NGS)提供了在短时间内对数百万亿个DNA序列进行测序的机会,从而导致了个性化医学的新应用,例如癌症诊断或抗病毒治疗。但是,测序技术具有不同的错误率,错误率在测序过程中会发生。如果将NGS数据用于诊断,则通常会忽略这些带有错误的序列,或者假定是最坏的情况。在当前的研究中,我们重点研究了含糊不清的碱对人类免疫缺陷病毒1(HIV-1)患者的治疗建议的影响。具体来说,我们基于共受体向性预测模型对采用进入阻断剂的治疗建议进行了分析。我们比较了文献中使用的三种不同的错误处理策略,即(i)忽略,(ii)最坏的假设,以及(iii)以多数票进行反卷积。我们可以证明,对于每个序列两个或多个歧义位置,通常不再可能进行可靠的预测。此外,歧义的立场也起着至关重要的作用。因此,针对上述错误处理策略,我们分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在不存在系统错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。歧义的立场也起着至关重要的作用。因此,我们针对上述错误处理策略分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在没有系统性错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。歧义的立场也起着至关重要的作用。因此,我们针对上述错误处理策略分析了现有测序技术(例如Illumina MiSeq或PacBio)的错误概率分布,结果发现在没有系统性错误的情况下,忽略优于其他策略。在其他情况下,应首选以多数票通过的反卷积策略。


























 京公网安备 11010802027423号
京公网安备 11010802027423号