npj Digital Medicine ( IF 12.4 ) Pub Date : 2020-03-26 , DOI: 10.1038/s41746-020-0256-0 Ji Hwan Park 1 , Han Eol Cho 2 , Jong Hun Kim 3 , Melanie M Wall 4 , Yaakov Stern 4, 5 , Hyunsun Lim 6 , Shinjae Yoo 1 , Hyoung Seop Kim 7 , Jiook Cha 4, 8, 9, 10
|
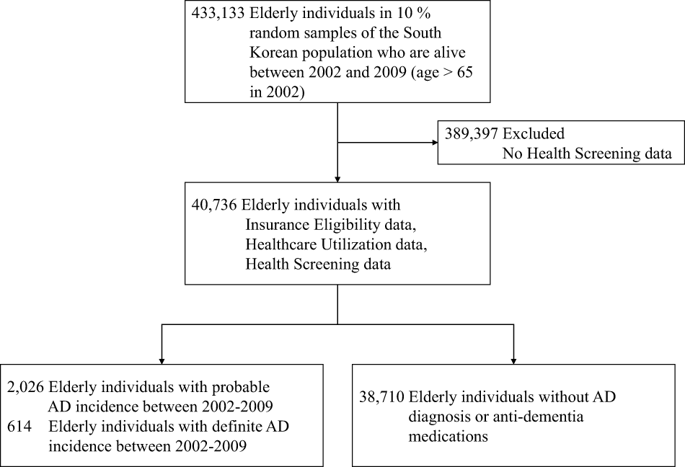
Nationwide population-based cohort provides a new opportunity to build an automated risk prediction model based on individuals’ history of health and healthcare beyond existing risk prediction models. We tested the possibility of machine learning models to predict future incidence of Alzheimer’s disease (AD) using large-scale administrative health data. From the Korean National Health Insurance Service database between 2002 and 2010, we obtained de-identified health data in elders above 65 years (N = 40,736) containing 4,894 unique clinical features including ICD-10 codes, medication codes, laboratory values, history of personal and family illness and socio-demographics. To define incident AD we considered two operational definitions: “definite AD” with diagnostic codes and dementia medication (n = 614) and “probable AD” with only diagnosis (n = 2026). We trained and validated random forest, support vector machine and logistic regression to predict incident AD in 1, 2, 3, and 4 subsequent years. For predicting future incidence of AD in balanced samples (bootstrapping), the machine learning models showed reasonable performance in 1-year prediction with AUC of 0.775 and 0.759, based on “definite AD” and “probable AD” outcomes, respectively; in 2-year, 0.730 and 0.693; in 3-year, 0.677 and 0.644; in 4-year, 0.725 and 0.683. The results were similar when the entire (unbalanced) samples were used. Important clinical features selected in logistic regression included hemoglobin level, age and urine protein level. This study may shed a light on the utility of the data-driven machine learning model based on large-scale administrative health data in AD risk prediction, which may enable better selection of individuals at risk for AD in clinical trials or early detection in clinical settings.
中文翻译:
使用大规模管理健康数据对阿尔茨海默病发病率进行机器学习预测
基于全国人口的队列提供了一个新的机会,可以根据个人的健康和医疗保健历史建立超越现有风险预测模型的自动风险预测模型。我们使用大规模管理健康数据测试了机器学习模型预测阿尔茨海默病 (AD) 未来发病率的可能性。我们从 2002 年至 2010 年间的韩国国民健康保险服务数据库中获得了 65 岁以上老年人 ( N = 40,736) 的去识别化健康数据,其中包含 4,894 个独特的临床特征,包括 ICD-10 代码、药物代码、实验室值、个人病史等。以及家庭疾病和社会人口统计。为了定义事件 AD,我们考虑了两种操作定义:带有诊断代码和痴呆药物的“确定 AD”( n = 614)和仅带有诊断的“可能 AD”( n = 2026)。我们训练并验证了随机森林、支持向量机和逻辑回归来预测随后 1、2、3 和 4 年的 AD 事件。为了预测平衡样本中 AD 的未来发病率(引导),机器学习模型在 1 年预测中表现出合理的性能,AUC 分别为 0.775 和 0.759,基于“确定的 AD”和“可能的 AD”结果; 2 年期为 0.730 和 0.693; 3 年期为 0.677 和 0.644; 4 年为 0.725 和 0.683。当使用整个(不平衡)样本时,结果相似。逻辑回归中选择的重要临床特征包括血红蛋白水平、年龄和尿蛋白水平。 这项研究可能揭示基于大规模管理健康数据的数据驱动机器学习模型在 AD 风险预测中的效用,这可能有助于在临床试验中更好地选择有 AD 风险的个体或在临床环境中进行早期检测。










































 京公网安备 11010802027423号
京公网安备 11010802027423号