当前位置:
X-MOL 学术
›
Comput. Graph. Forum
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A Cross‐Dimension Annotations Method for 3D Structural Facial Landmark Extraction
Computer Graphics Forum ( IF 2.7 ) Pub Date : 2019-12-27 , DOI: 10.1111/cgf.13895 Xun Gong 1 , Ping Chen 1 , Zhemin Zhang 1 , Ke Chen 1 , Yue Xiang 2 , Xin Li 3
Computer Graphics Forum ( IF 2.7 ) Pub Date : 2019-12-27 , DOI: 10.1111/cgf.13895 Xun Gong 1 , Ping Chen 1 , Zhemin Zhang 1 , Ke Chen 1 , Yue Xiang 2 , Xin Li 3
Affiliation
|
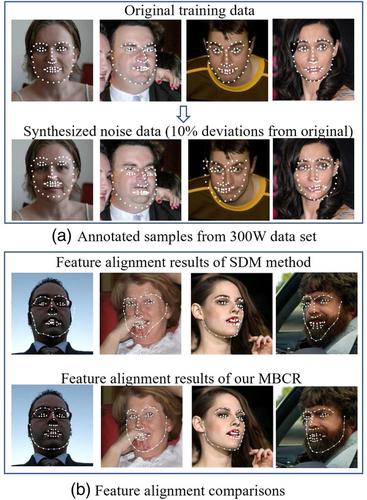
Recent methods for 2D facial landmark localization perform well on close‐to‐frontal faces, but 2D landmarks are insufficient to represent 3D structure of a facial shape. For applications that require better accuracy, such as facial motion capture and 3D shape recovery, 3DA‐2D (2D Projections of 3D Facial Annotations) is preferred. Inferring the 3D structure from a single image is an ill‐posed problem whose accuracy and robustness are not always guaranteed. This paper aims to solve accurate 2D facial landmark localization and the transformation between 2D and 3DA‐2D landmarks. One way to increase the accuracy is to input more precisely annotated facial images. The traditional cascaded regressions cannot effectively handle large or noisy training data sets. In this paper, we propose a Mini‐Batch Cascaded Regressions (MBCR) method that can iteratively train a robust model from a large data set. Benefiting from the incremental learning strategy and a small learning rate, MBCR is robust to noise in training data. We also propose a new Cross‐Dimension Annotations Conversion (CDAC) method to map facial landmarks from 2D to 3DA‐2D coordinates and vice versa. The experimental results showed that CDAC combined with MBCR outperforms the‐state‐of‐the‐art methods in 3DA‐2D facial landmark localization. Moreover, CDAC can run efficiently at up to 110 fps on a 3.4 GHz‐CPU workstation. Thus, CDAC provides a solution to transform existing 2D alignment methods into 3DA‐2D ones without slowing down the speed. Training and testing code as well as the data set can be downloaded from https://github.com/SWJTU‐3DVision/CDAC.
中文翻译:

一种用于 3D 结构人脸地标提取的跨维度标注方法
最近用于 2D 面部标志定位的方法在接近正面的面部上表现良好,但 2D 标志不足以表示面部形状的 3D 结构。对于需要更高准确性的应用,例如面部运动捕捉和 3D 形状恢复,3DA-2D(3D 面部注释的 2D 投影)是首选。从单个图像推断 3D 结构是一个不适定问题,其准确性和鲁棒性并不总是得到保证。本文旨在解决准确的 2D 面部标志定位以及 2D 和 3DA-2D 标志之间的转换。提高准确性的一种方法是输入更精确注释的面部图像。传统的级联回归无法有效处理大型或嘈杂的训练数据集。在本文中,我们提出了一种 Mini-Batch Cascaded Regressions (MBCR) 方法,该方法可以从大数据集中迭代训练一个健壮的模型。受益于增量学习策略和较小的学习率,MBCR 对训练数据中的噪声具有鲁棒性。我们还提出了一种新的跨维度注释转换(CDAC)方法来将面部标志从 2D 映射到 3DA-2D 坐标,反之亦然。实验结果表明,CDAC 结合 MBCR 在 3DA-2D 面部标志定位方面优于最先进的方法。此外,CDAC 可以在 3.4 GHz-CPU 工作站上以高达 110 fps 的速度高效运行。因此,CDAC 提供了一种解决方案,可以在不降低速度的情况下将现有的 2D 对齐方法转换为 3DA-2D 对齐方法。训练和测试代码以及数据集可以从 https://github.com/SWJTU-3DVision/CDAC 下载。
更新日期:2019-12-27
中文翻译:
一种用于 3D 结构人脸地标提取的跨维度标注方法
最近用于 2D 面部标志定位的方法在接近正面的面部上表现良好,但 2D 标志不足以表示面部形状的 3D 结构。对于需要更高准确性的应用,例如面部运动捕捉和 3D 形状恢复,3DA-2D(3D 面部注释的 2D 投影)是首选。从单个图像推断 3D 结构是一个不适定问题,其准确性和鲁棒性并不总是得到保证。本文旨在解决准确的 2D 面部标志定位以及 2D 和 3DA-2D 标志之间的转换。提高准确性的一种方法是输入更精确注释的面部图像。传统的级联回归无法有效处理大型或嘈杂的训练数据集。在本文中,我们提出了一种 Mini-Batch Cascaded Regressions (MBCR) 方法,该方法可以从大数据集中迭代训练一个健壮的模型。受益于增量学习策略和较小的学习率,MBCR 对训练数据中的噪声具有鲁棒性。我们还提出了一种新的跨维度注释转换(CDAC)方法来将面部标志从 2D 映射到 3DA-2D 坐标,反之亦然。实验结果表明,CDAC 结合 MBCR 在 3DA-2D 面部标志定位方面优于最先进的方法。此外,CDAC 可以在 3.4 GHz-CPU 工作站上以高达 110 fps 的速度高效运行。因此,CDAC 提供了一种解决方案,可以在不降低速度的情况下将现有的 2D 对齐方法转换为 3DA-2D 对齐方法。训练和测试代码以及数据集可以从 https://github.com/SWJTU-3DVision/CDAC 下载。










































 京公网安备 11010802027423号
京公网安备 11010802027423号