当前位置:
X-MOL 学术
›
WIREs Data Mining Knowl. Discov.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Density‐based clustering
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2019-10-29 , DOI: 10.1002/widm.1343 Ricardo J. G. B. Campello 1 , Peer Kröger 2 , Jörg Sander 3 , Arthur Zimek 4
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2019-10-29 , DOI: 10.1002/widm.1343 Ricardo J. G. B. Campello 1 , Peer Kröger 2 , Jörg Sander 3 , Arthur Zimek 4
Affiliation
|
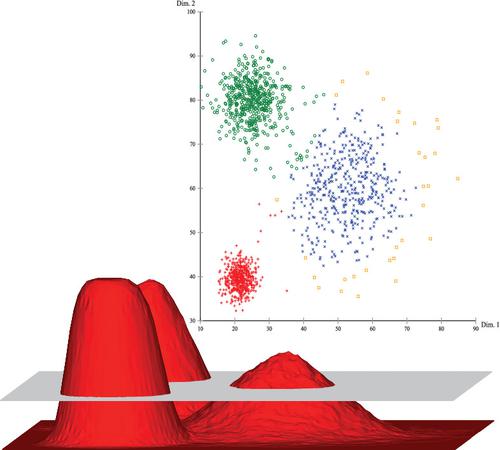
Clustering refers to the task of identifying groups or clusters in a data set. In density‐based clustering, a cluster is a set of data objects spread in the data space over a contiguous region of high density of objects. Density‐based clusters are separated from each other by contiguous regions of low density of objects. Data objects located in low‐density regions are typically considered noise or outliers. In this review article we discuss the statistical notion of density‐based clusters, classic algorithms for deriving a flat partitioning of density‐based clusters, methods for hierarchical density‐based clustering, and methods for semi‐supervised clustering. We conclude with some open challenges related to density‐based clustering.
中文翻译:

基于密度的聚类
聚类是指识别数据集中的组或聚类的任务。在基于密度的集群中,集群是一组数据对象,它们分布在数据空间中高密度对象的连续区域上。基于密度的群集通过低密度对象的连续区域彼此分开。位于低密度区域的数据对象通常被认为是噪声或离群值。在这篇综述文章中,我们讨论基于密度的聚类的统计概念,用于推导基于密度的聚类的平面划分的经典算法,基于层次的密度聚类的方法以及半监督聚类的方法。最后,我们提出了一些与基于密度的聚类相关的挑战。
更新日期:2019-10-29
中文翻译:
基于密度的聚类
聚类是指识别数据集中的组或聚类的任务。在基于密度的集群中,集群是一组数据对象,它们分布在数据空间中高密度对象的连续区域上。基于密度的群集通过低密度对象的连续区域彼此分开。位于低密度区域的数据对象通常被认为是噪声或离群值。在这篇综述文章中,我们讨论基于密度的聚类的统计概念,用于推导基于密度的聚类的平面划分的经典算法,基于层次的密度聚类的方法以及半监督聚类的方法。最后,我们提出了一些与基于密度的聚类相关的挑战。










































 京公网安备 11010802027423号
京公网安备 11010802027423号