Information Sciences Pub Date : 2020-03-17 , DOI: 10.1016/j.ins.2020.03.028 Nuha Zamzami , Nizar Bouguila
|
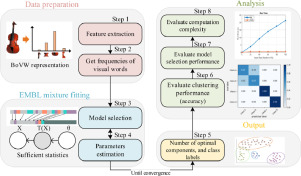
In this paper, we propose a mixture model for high-dimensional count data clustering based on an exponential-family approximation of the Multinomial Beta-Liouville distribution, which we call EMBL. We deal simultaneously with the problems of fitting the model to observed data and selecting the number of components. The learning algorithm automatically selects the optimal number of components and avoids several drawbacks of the standard Expectation-Maximization algorithm, including the sensitivity to initialization and possible convergence to the boundary of the parameter space. We demonstrate the effectiveness and robustness of the proposed clustering approach through a set of extensive empirical experiments that involve challenging real-world applications. The results reveal that the novel proposed model strives to achieve higher accuracy compared to the state-of-the-art generative models for count data clustering. Furthermore, the superior performance of EMBL demonstrates its flexibility and ability to address the burstiness phenomenon successfully, as well as shows its computational efficiency, especially when dealing with sparse high-dimensional vectors.
中文翻译:
基于对多项式Beta-Liouville分布的指数近似的高维计数数据聚类
在本文中,我们提出了基于多项式Beta-Liouville分布的指数族近似的高维计数数据聚类的混合模型,我们将其称为EMBL。我们同时处理将模型拟合到观测数据并选择组件数量的问题。学习算法会自动选择最佳的组件数量,并避免了标准Expectation-Maximization算法的几个缺点,包括对初始化的敏感性以及可能收敛到参数空间边界的问题。我们通过涉及挑战性现实应用的一系列广泛的经验实验证明了所提出的聚类方法的有效性和鲁棒性。结果表明,与最新的用于计数数据聚类的生成模型相比,提出的新模型力求实现更高的准确性。此外,EMBL的优越性能证明了它的灵活性和成功解决突发现象的能力,并显示了其计算效率,尤其是在处理稀疏高维向量时。








































 京公网安备 11010802027423号
京公网安备 11010802027423号