Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
Different strategies for class model optimization. A comparative study.
Talanta ( IF 6.1 ) Pub Date : 2020-03-12 , DOI: 10.1016/j.talanta.2020.120912 Zuzanna Małyjurek 1 , Raffaele Vitale 2 , Beata Walczak 1
Talanta ( IF 6.1 ) Pub Date : 2020-03-12 , DOI: 10.1016/j.talanta.2020.120912 Zuzanna Małyjurek 1 , Raffaele Vitale 2 , Beata Walczak 1
Affiliation
|
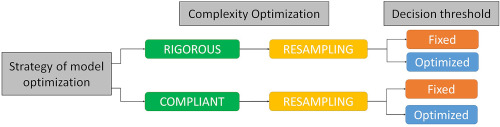
The Class Modelling (CM) approaches like Soft Independent Modelling of Class Analogy (SIMCA) aim at developing a mathematical model for determination of belongingness of new samples to the studied classes. The main feature of CM is that for each target class an individual model is constructed. CM is widely exploited, e.g., in the food and drug quality testing and authenticity or origin verification. It is well known that the most critical stage in construction of a class model is optimization of its parameters. There exist two basic strategies for optimization of class model, i.e., the "compliant" strategy where the target and nontarget class samples are required in the model optimization process, and the "rigorous" strategy where only the target class samples are used. Since the nontarget class samples are usually available, the compliant scenario is more often explored. In the present study, four different resampling methods for optimization of the SIMCA model (applied in both, a compliant and a rigorous fashion) are thoroughly compared. Each method is tested in combination with two distinct decision threshold estimation criteria: i) an a priori fixing it based on a desired statistical significance level and ii) optimizing it through appropriate data-driven procedures. For the sake of a comprehensive assessment of the studied strategies, several real-world datasets are exploited and final results are post-processed by means of ANalysis Of VAriance (ANOVA). The study reveals that both, a compliant approach with an optimized decision threshold and a rigorous approach with a fixed decision threshold can yield satisfactory classification outcomes, no matter which resampling technique is used. Finally, it is shown how unrepresentativeness of the nontarget classes can lead to the biased classification models when a compliant optimization is carried out. Therefore, a rigorous optimization can be considered as a safer option for the SIMCA model parameter tuning.
中文翻译:

类模型优化的不同策略。一项比较研究。
类建模(CM)方法(如类比的软独立建模(SIMCA))旨在开发一种数学模型,用于确定新样本对所研究类的归属。CM的主要特征是针对每个目标类别构建一个单独的模型。CM被广泛利用,例如在食品和药品质量测试以及真实性或原产地验证中。众所周知,构建类模型的最关键阶段是优化其参数。存在两种用于优化类别模型的基本策略,即在模型优化过程中需要目标和非目标类别样本的“顺从”策略,以及仅使用目标类别样本的“严格”策略。由于通常可以使用非目标类别的样本,符合要求的场景通常会被探索。在本研究中,对用于SIMCA模型优化的四种不同的重采样方法(以顺应性和严格方式同时应用)进行了全面比较。每种方法均与两个不同的决策阈值估计标准结合进行测试:i)根据所需的统计显着性水平进行先验固定; ii)通过适当的数据驱动程序对其进行优化。为了全面评估所研究的策略,我们利用了多个真实世界的数据集,并通过变异分析(ANOVA)对最终结果进行了后处理。研究表明,具有最佳决策阈值的顺应方法和具有固定决策阈值的严格方法都可以产生令人满意的分类结果,无论使用哪种重采样技术。最后,显示了当执行顺应性优化时,非目标类的不代表性如何导致偏向分类模型。因此,对于SIMCA模型参数调整,严格的优化可以被视为更安全的选择。
更新日期:2020-03-12
中文翻译:
类模型优化的不同策略。一项比较研究。
类建模(CM)方法(如类比的软独立建模(SIMCA))旨在开发一种数学模型,用于确定新样本对所研究类的归属。CM的主要特征是针对每个目标类别构建一个单独的模型。CM被广泛利用,例如在食品和药品质量测试以及真实性或原产地验证中。众所周知,构建类模型的最关键阶段是优化其参数。存在两种用于优化类别模型的基本策略,即在模型优化过程中需要目标和非目标类别样本的“顺从”策略,以及仅使用目标类别样本的“严格”策略。由于通常可以使用非目标类别的样本,符合要求的场景通常会被探索。在本研究中,对用于SIMCA模型优化的四种不同的重采样方法(以顺应性和严格方式同时应用)进行了全面比较。每种方法均与两个不同的决策阈值估计标准结合进行测试:i)根据所需的统计显着性水平进行先验固定; ii)通过适当的数据驱动程序对其进行优化。为了全面评估所研究的策略,我们利用了多个真实世界的数据集,并通过变异分析(ANOVA)对最终结果进行了后处理。研究表明,具有最佳决策阈值的顺应方法和具有固定决策阈值的严格方法都可以产生令人满意的分类结果,无论使用哪种重采样技术。最后,显示了当执行顺应性优化时,非目标类的不代表性如何导致偏向分类模型。因此,对于SIMCA模型参数调整,严格的优化可以被视为更安全的选择。


























 京公网安备 11010802027423号
京公网安备 11010802027423号