当前位置:
X-MOL 学术
›
J. Biomed. Inform.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Matching patients to clinical trials using semantically enriched document representation.
Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-03-10 , DOI: 10.1016/j.jbi.2020.103406 Hamed Hassanzadeh 1 , Sarvnaz Karimi 2 , Anthony Nguyen 1
Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-03-10 , DOI: 10.1016/j.jbi.2020.103406 Hamed Hassanzadeh 1 , Sarvnaz Karimi 2 , Anthony Nguyen 1
Affiliation
|
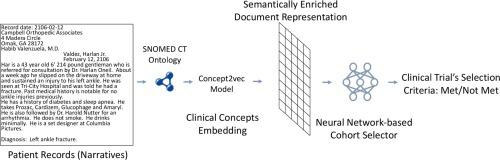
Recruiting eligible patients for clinical trials is crucial for reliably answering specific questions about medical interventions and evaluation. However, clinical trial recruitment is a bottleneck in clinical research and drug development. Our goal is to provide an approach towards automating this manual and time-consuming patient recruitment task using natural language processing and machine learning techniques. Specifically, our approach extracts key information from series of narrative clinical documents in patient's records and collates helpful evidence to make decisions on eligibility of patients according to certain inclusion and exclusion criteria. Challenges in applying narrative clinical documents such as differences in reporting styles and sub-languages are addressed by enriching them with knowledge from domain ontologies in the form of semantic vector representations. We show that a machine learning model based on Multi-Layer Perceptron (MLP) is more effective for the task than five other neural networks and four conventional machine learning models. Our approach achieves overall micro-F1-Score of 84% for 13 different eligibility criteria. Our experiments also indicate that semantically enriched documents are more effective than using original documents for cohort selection. Our system provides an end-to-end machine learning-based solution that achieves comparable results with the state-of-the-art which relies on hand-crafted rules or data-centric engineered features.
中文翻译:

使用语义丰富的文档表示将患者匹配到临床试验。
招募合格的患者进行临床试验对于可靠地回答有关医疗干预和评估的特定问题至关重要。但是,临床试验招募是临床研究和药物开发的瓶颈。我们的目标是提供一种使用自然语言处理和机器学习技术自动执行此手动且耗时的患者招募任务的方法。具体来说,我们的方法从患者记录中的一系列叙述性临床文件中提取关键信息,并整理有用的证据,以根据某些纳入和排除标准来决定患者的资格。通过使用语义载体表示形式的领域本体知识来丰富叙事性临床文档,例如报告风格和副语言方面的差异,可以解决这些挑战。我们表明,基于多层感知器(MLP)的机器学习模型比其他五个神经网络和四个常规机器学习模型更有效。对于13种不同的资格标准,我们的方法可实现84%的总体micro-F1-分数。我们的实验还表明,语义丰富的文档比使用原始文档进行同类群组选择更为有效。我们的系统提供了一种基于端到端机器学习的解决方案,该解决方案可以与依靠手工制定的规则或以数据为中心的工程设计特征的最新技术相媲美。
更新日期:2020-04-21
中文翻译:
使用语义丰富的文档表示将患者匹配到临床试验。
招募合格的患者进行临床试验对于可靠地回答有关医疗干预和评估的特定问题至关重要。但是,临床试验招募是临床研究和药物开发的瓶颈。我们的目标是提供一种使用自然语言处理和机器学习技术自动执行此手动且耗时的患者招募任务的方法。具体来说,我们的方法从患者记录中的一系列叙述性临床文件中提取关键信息,并整理有用的证据,以根据某些纳入和排除标准来决定患者的资格。通过使用语义载体表示形式的领域本体知识来丰富叙事性临床文档,例如报告风格和副语言方面的差异,可以解决这些挑战。我们表明,基于多层感知器(MLP)的机器学习模型比其他五个神经网络和四个常规机器学习模型更有效。对于13种不同的资格标准,我们的方法可实现84%的总体micro-F1-分数。我们的实验还表明,语义丰富的文档比使用原始文档进行同类群组选择更为有效。我们的系统提供了一种基于端到端机器学习的解决方案,该解决方案可以与依靠手工制定的规则或以数据为中心的工程设计特征的最新技术相媲美。










































 京公网安备 11010802027423号
京公网安备 11010802027423号