Journal of Biomedical informatics ( IF 4.0 ) Pub Date : 2020-03-06 , DOI: 10.1016/j.jbi.2020.103399 Braja Gopal Patra 1 , Vahed Maroufy 1 , Babak Soltanalizadeh 1 , Nan Deng 1 , W Jim Zheng 2 , Kirk Roberts 2 , Hulin Wu 3
|
Objective
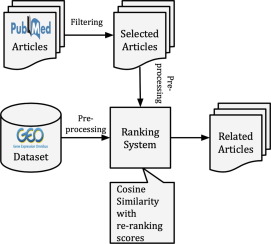
The centrality of data to biomedical research is difficult to understate, and the same is true for the importance of the biomedical literature in disseminating empirical findings to scientific questions made on such data. But the connections between the literature and related datasets are often weak, hampering the ability of scientists to easily move between existing datasets and existing findings to derive new scientific hypotheses. This work aims to recommend relevant literature articles for datasets with the ultimate goal of increasing the productivity of researchers. Our approach to literature recommendation for datasets is a part of the dataset reusability platform developed at the University Texas Health Science Center at Houston for datasets related to gene expression. This platform incorporates datasets from Gene Expression Omnibus (GEO). An average of 34 datasets were added to GEO daily in the last five years (i.e. 2014 to 2018), demonstrating the need for automatic methods to connect these datasets with relevant literature. The relevant literature for a given dataset may describe that dataset, provide a scientific finding based on that dataset, or even describe prior and related work to the dataset’s topic that is of interest to users of the dataset.
Materials and Methods
We adopt an information retrieval paradigm for literature recommendation. In our experiments, distributional semantic features are created from the title and abstract of MEDLINE articles. Then, related articles are identified for datasets in GEO. We evaluate multiple distributional methods such as TF-IDF, BM25, Latent Semantic Analysis, Latent Dirichlet Allocation, word2vec, and doc2vec. Top similar papers are recommended for each dataset using cosine similarity between the dataset’s vector representation and every paper’s vector representation. We also propose several novel re-ranking and normalization methods over embeddings to improve the recommendations.
Results
The top-performing literature recommendation technique achieved a strict precision at 10 of 0.8333 and a partial precision at 10 of 0.9000 using BM25 based on a manual evaluation of 36 datasets. Evaluation on a larger, automatically-collected benchmark shows small but consistent gains by emphasizing the similarity of dataset and article titles.
Conclusion
This work is the first step toward developing a literature recommendation tool by recommending relevant literature for datasets. This will hopefully lead to better data reuse experience.
中文翻译:
基于内容的数据推荐文献推荐系统,可提高数据的可重用性-以基因表达综合(GEO)数据集为例
目的
数据在生物医学研究中的中心性很难被低估,生物医学文献在将实证发现传播到对此类数据提出的科学问题的重要性方面也是如此。但是,文献与相关数据集之间的联系通常很薄弱,从而妨碍了科学家在现有数据集和现有发现之间轻松移动以得出新的科学假设的能力。这项工作旨在为数据集推荐相关的文献文章,其最终目标是提高研究人员的生产率。我们对数据集进行文献推荐的方法是在休斯顿的德克萨斯大学健康科学中心针对与基因表达相关的数据集开发的数据集可重用性平台的一部分。该平台整合了Gene Expression Omnibus(GEO)的数据集。在过去的五年(即2014年至2018年)中,每天平均有34个数据集被添加到GEO中,这表明需要采用自动方法将这些数据集与相关文献相连接。给定数据集的相关文献可以描述该数据集,基于该数据集提供科学发现,甚至描述该数据集用户感兴趣的数据集主题的先前工作和相关工作。
材料和方法
我们采用信息检索范例进行文献推荐。在我们的实验中,分布式语义特征是根据MEDLINE文章的标题和摘要创建的。然后,为GEO中的数据集识别相关文章。我们评估了多种分布方法,例如TF-IDF,BM25,潜在语义分析,潜在Dirichlet分配,word2vec和doc2vec。建议使用数据集的矢量表示与每篇论文的矢量表示之间的余弦相似度为每个数据集提供相似的论文。我们还针对嵌入提出了几种新颖的重新排序和规范化方法,以改善建议。
结果
表现最佳的文献推荐技术使用BM25基于36个数据集的人工评估,获得了10的严格精度0.8333和10的局部精度0.9000。通过强调数据集和文章标题的相似性,对较大的,自动收集的基准进行评估显示出较小但一致的收益。
结论
通过为数据集推荐相关文献,这项工作是开发文献推荐工具的第一步。希望这将带来更好的数据重用体验。










































 京公网安备 11010802027423号
京公网安备 11010802027423号