Computational and Structural Biotechnology Journal ( IF 4.4 ) Pub Date : 2020-02-04 , DOI: 10.1016/j.csbj.2020.01.012 Pablo Mier 1 , Carlos Elena-Real 2 , Annika Urbanek 2 , Pau Bernadó 2 , Miguel A Andrade-Navarro 1
|
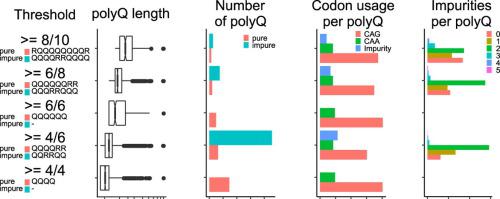
Polyglutamine (polyQ) regions are one of the most prevalent homorepeats in eukaryotes. It is however difficult to evaluate their prevalence because various studies claim different results. The reason is the lack of a consensus to define what is indeed a polyQ region. We have tackled this issue by studying how the use of different thresholds (i.e., minimum number of glutamines required in a protein region of a given size), to detect polyQ regions in the human proteome influences not only their prevalence but also their general features and sequence context. Threshold definition shapes the length distribution of the polyQ dataset, and changes the observed number and position of impurities (amino acids other than glutamine) within polyQ regions. Irrespective of the chosen threshold, leucine and proline residues are enriched both within and around polyQ. While leucine is enriched at the N-terminus of polyQ and specially at position −1 (amino acid preceding the polyQ), proline is prevalent in the C-terminus (positions +1 to +5, that is, the first five amino acids after the polyQ). We also checked the suitability of these thresholds for other species, and compared their polyQ features with those found in humans. As the sequence context and features of polyQ regions are threshold-dependent, we propose a method to quickly scan the polyQ landscape of a proteome. We complement our results with a summarized overview about which biases are to be expected per threshold when studying polyQ regions.
中文翻译:
定义在 PolyQ 区域研究中的重要性:阈值、杂质和序列背景的故事。
聚谷氨酰胺(polyQ)区域是真核生物中最常见的同源重复区域之一。然而,评估其患病率很困难,因为各种研究得出了不同的结果。原因是缺乏共识来定义什么是真正的 PolyQ 区域。我们通过研究使用不同的阈值(即给定大小的蛋白质区域中所需的谷氨酰胺的最小数量)来检测人类蛋白质组中的 PolyQ 区域如何不仅影响其患病率,而且影响其一般特征和特征,从而解决了这个问题。序列上下文。阈值定义塑造了polyQ数据集的长度分布,并改变了polyQ区域内观察到的杂质(谷氨酰胺以外的氨基酸)的数量和位置。无论选择的阈值如何,亮氨酸和脯氨酸残基都会在 PolyQ 内部和周围富集。虽然亮氨酸富集在 polyQ 的 N 端,特别是位置 -1(polyQ 前面的氨基酸),但脯氨酸普遍存在于 C 端(位置 +1 到 +5,即后面的前五个氨基酸)聚Q)。我们还检查了这些阈值对其他物种的适用性,并将它们的 PolyQ 特征与人类中发现的特征进行了比较。由于polyQ区域的序列背景和特征是阈值相关的,我们提出了一种快速扫描蛋白质组的polyQ景观的方法。我们通过总结概述来补充我们的结果,了解在研究 polyQ 区域时每个阈值预期存在哪些偏差。










































 京公网安备 11010802027423号
京公网安备 11010802027423号