Artificial Intelligence in Medicine ( IF 6.1 ) Pub Date : 2020-02-10 , DOI: 10.1016/j.artmed.2020.101815 Nonso Nnamoko 1 , Ioannis Korkontzelos 1
|
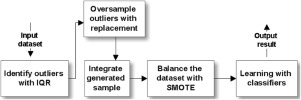
Learning from outliers and imbalanced data remains one of the major difficulties for machine learning classifiers. Among the numerous techniques dedicated to tackle this problem, data preprocessing solutions are known to be efficient and easy to implement. In this paper, we propose a selective data preprocessing approach that embeds knowledge of the outlier instances into artificially generated subset to achieve an even distribution. The Synthetic Minority Oversampling TEchnique (SMOTE) was used to balance the training data by introducing artificial minority instances. However, this was not before the outliers were identified and oversampled (irrespective of class). The aim is to balance the training dataset while controlling the effect of outliers. The experiments prove that such selective oversampling empowers SMOTE, ultimately leading to improved classification performance.
中文翻译:
有效治疗异常值和类别失衡以预测糖尿病。
从异常值和不平衡数据中学习仍然是机器学习分类器的主要困难之一。在致力于解决此问题的众多技术中,众所周知,数据预处理解决方案高效且易于实施。在本文中,我们提出了一种选择性数据预处理方法,将异常值实例的知识嵌入到人工生成的子集中以实现均匀分布。合成少数过采样技术 (SMOTE) 用于通过引入人工少数实例来平衡训练数据。然而,这不是在异常值被识别和过采样之前(不考虑类别)。目的是平衡训练数据集,同时控制异常值的影响。实验证明,这种选择性过采样赋予了 SMOTE,










































 京公网安备 11010802027423号
京公网安备 11010802027423号