当前位置:
X-MOL 学术
›
Drug Test. Anal.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A machine learning approach for handling big data produced by high resolution mass spectrometry after data independent acquisition of small molecules - Proof of concept study using an artificial neural network for sample classification.
Drug Testing and Analysis ( IF 2.6 ) Pub Date : 2020-02-06 , DOI: 10.1002/dta.2775 Gabriel L Streun 1 , Marco P Elmiger 1 , Akos Dobay 2, 3 , Lars Ebert 3 , Thomas Kraemer 1
Drug Testing and Analysis ( IF 2.6 ) Pub Date : 2020-02-06 , DOI: 10.1002/dta.2775 Gabriel L Streun 1 , Marco P Elmiger 1 , Akos Dobay 2, 3 , Lars Ebert 3 , Thomas Kraemer 1
Affiliation
|
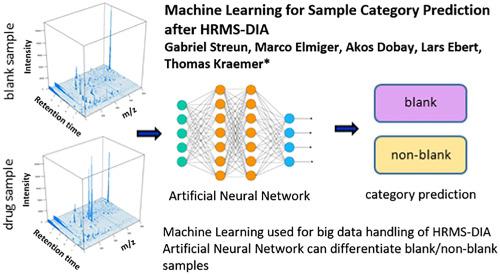
Liquid chromatography coupled to high‐resolution mass spectrometry (HRMS) enables data independent acquisition (DIA) and untargeted screening. However, to avoid the handling of the resulting large dataset, most laboratories in that field still use targeted screening methods, which offer good sensitivity and specificity but are limited to known compounds. The promising field of machine learning offers new possibilities such as artificial neural networks that can be trained to classify large amounts of data. In this proof of concept study, we exemplify such a machine learning approach for raw HRMS‐DIA data files. We evaluated a machine learning model using training, validation, and test sets of solvent and whole blood samples containing drugs (of abuse) common in forensic toxicology. For that purpose, different platforms were used. With a feedforward neural network model architecture, a category prediction (blank sample vs. drug containing sample) was aimed for. With the applied machine learning approaches, the sensitivity and specificity, of the validation and test set, for the prediction of sample classes were in a suitable range for an actual use in a (routine) laboratory (e.g. workplace drug testing). In conclusion, this proof of concept study clearly demonstrated the huge potential of machine learning in the analysis of HRMS‐DIA data.
中文翻译:

在独立于小分子的数据采集之后,用于处理由高分辨率质谱法产生的大数据的机器学习方法-使用人工神经网络进行样品分类的概念验证研究。
液相色谱与高分辨率质谱法(HRMS)结合使用可实现数据独立采集(DIA)和非目标筛选。但是,为避免处理所得的大型数据集,该领域中的大多数实验室仍使用靶向筛选方法,该方法具有良好的灵敏度和特异性,但仅限于已知化合物。有前途的机器学习领域提供了新的可能性,例如可以训练以对大量数据进行分类的人工神经网络。在此概念验证研究中,我们为原始HRMS-DIA数据文件举例说明了这种机器学习方法。我们使用训练,验证和包含法医毒理学中常见的(滥用)药物的溶剂和全血样本测试集评估了机器学习模型。为此,使用了不同的平台。通过前馈神经网络模型架构,可以实现类别预测(空白样品与含药样品)。使用应用的机器学习方法,验证和测试集对样品类别的预测的敏感性和特异性在(常规)实验室中实际使用(例如工作场所药物测试)的合适范围内。总之,这一概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。工作场所药物测试)。总之,这项概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。工作场所药物测试)。总之,这项概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。
更新日期:2020-02-06
中文翻译:
在独立于小分子的数据采集之后,用于处理由高分辨率质谱法产生的大数据的机器学习方法-使用人工神经网络进行样品分类的概念验证研究。
液相色谱与高分辨率质谱法(HRMS)结合使用可实现数据独立采集(DIA)和非目标筛选。但是,为避免处理所得的大型数据集,该领域中的大多数实验室仍使用靶向筛选方法,该方法具有良好的灵敏度和特异性,但仅限于已知化合物。有前途的机器学习领域提供了新的可能性,例如可以训练以对大量数据进行分类的人工神经网络。在此概念验证研究中,我们为原始HRMS-DIA数据文件举例说明了这种机器学习方法。我们使用训练,验证和包含法医毒理学中常见的(滥用)药物的溶剂和全血样本测试集评估了机器学习模型。为此,使用了不同的平台。通过前馈神经网络模型架构,可以实现类别预测(空白样品与含药样品)。使用应用的机器学习方法,验证和测试集对样品类别的预测的敏感性和特异性在(常规)实验室中实际使用(例如工作场所药物测试)的合适范围内。总之,这一概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。工作场所药物测试)。总之,这项概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。工作场所药物测试)。总之,这项概念验证研究清楚地证明了在HRMS-DIA数据分析中机器学习的巨大潜力。










































 京公网安备 11010802027423号
京公网安备 11010802027423号