当前位置:
X-MOL 学术
›
Sci. Total Environ.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Enhancing nitrate and strontium concentration prediction in groundwater by using new data mining algorithm.
Science of the Total Environment ( IF 8.2 ) Pub Date : 2020-01-24 , DOI: 10.1016/j.scitotenv.2020.136836 Dieu Tien Bui 1 , Khabat Khosravi 2 , Mahshid Karimi 3 , Gianluigi Busico 4 , Zohreh Sheikh Khozani 5 , Hoang Nguyen 6 , Micol Mastrocicco 4 , Dario Tedesco 7 , Emilio Cuoco 4 , Nerantzis Kazakis 8
Science of the Total Environment ( IF 8.2 ) Pub Date : 2020-01-24 , DOI: 10.1016/j.scitotenv.2020.136836 Dieu Tien Bui 1 , Khabat Khosravi 2 , Mahshid Karimi 3 , Gianluigi Busico 4 , Zohreh Sheikh Khozani 5 , Hoang Nguyen 6 , Micol Mastrocicco 4 , Dario Tedesco 7 , Emilio Cuoco 4 , Nerantzis Kazakis 8
Affiliation
|
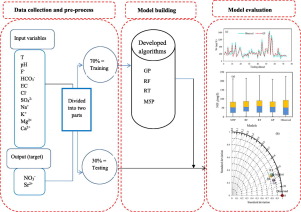
Groundwater resources constitute the main source of clean fresh water for domestic use and it is essential for food production in the agricultural sector. Groundwater has a vital role for water supply in the Campanian Plain in Italy and hence a future sustainability of the resource is essential for the region. In the current paper novel data mining algorithms including Gaussian Process (GP) were used in a large groundwater quality database to predict nitrate (contaminant) and strontium (potential future increasing) concentrations in groundwater. The results were compared with M5P, random forest (RF) and random tree (RT) algorithms as a benchmark to test the robustness of the modeling process. The dataset includes 246 groundwater quality samples originating from different wells, municipals and agricultural. It was divided for the modeling process into two subgroups by using the 10-fold cross validation technique including 173 samples for model building (training dataset) and 73 samples for model validation (testing dataset). Different water quality variables including T, pH, EC, HCO3-, F-, Cl-, SO42-, Na+, K+, Mg2+, and Ca2+ have been used as an input to the models. At first stage, different input combinations have been constructed based on correlation coefficient and thus the optimal combination was chosen for the modeling phase. Different quantitative criteria alongside with visual comparison approach have been used for evaluating the modeling capability. Results revealed that to obtain reliable results also variables with low correlation should be considered as an input to the models together with those variables showing high correlation coefficients. According to the model evaluation criteria, GP algorithm outperforms all the other models in predicting both nitrate and strontium concentrations followed by RF, M5P and RT, respectively. Result also revealed that model's structure together with the accuracy and structure of the data can have a relevant impact on the model's results.
中文翻译:

利用新的数据挖掘算法增强地下水中硝酸盐和锶的浓度预测。
地下水资源是供家庭使用的清洁淡水的主要来源,对农业部门的粮食生产至关重要。地下水对意大利坎帕尼亚平原的供水至关重要,因此,该地区未来资源的可持续性至关重要。在当前的论文中,包括高斯过程(GP)在内的新型数据挖掘算法被用于大型地下水质量数据库中,以预测地下水中的硝酸盐(污染物)和锶(潜在的未来增加浓度)。将结果与M5P,随机森林(RF)和随机树(RT)算法进行比较,以测试建模过程的鲁棒性。该数据集包括来自不同井,市政和农业的246个地下水质量样本。通过使用10倍交叉验证技术,将建模过程分为两个子组,包括173个用于模型构建的样本(训练数据集)和73个用于模型验证的模型(测试数据集)。模型使用了不同的水质变量,包括T,pH,EC,HCO3-,F-,Cl-,SO42-,Na +,K +,Mg2 +和Ca2 +。在第一阶段,已基于相关系数构造了不同的输入组合,因此为建模阶段选择了最佳组合。不同的定量标准以及视觉比较方法已用于评估建模能力。结果表明,为了获得可靠的结果,还应将具有低相关性的变量与显示高相关系数的那些变量一起考虑为模型的输入。根据模型评估标准,GP算法在预测硝酸盐和锶的浓度,其次分别为RF,M5P和RT时,优于所有其他模型。结果还表明,模型的结构以及数据的准确性和结构可能会对模型的结果产生相关影响。
更新日期:2020-01-24
中文翻译:
利用新的数据挖掘算法增强地下水中硝酸盐和锶的浓度预测。
地下水资源是供家庭使用的清洁淡水的主要来源,对农业部门的粮食生产至关重要。地下水对意大利坎帕尼亚平原的供水至关重要,因此,该地区未来资源的可持续性至关重要。在当前的论文中,包括高斯过程(GP)在内的新型数据挖掘算法被用于大型地下水质量数据库中,以预测地下水中的硝酸盐(污染物)和锶(潜在的未来增加浓度)。将结果与M5P,随机森林(RF)和随机树(RT)算法进行比较,以测试建模过程的鲁棒性。该数据集包括来自不同井,市政和农业的246个地下水质量样本。通过使用10倍交叉验证技术,将建模过程分为两个子组,包括173个用于模型构建的样本(训练数据集)和73个用于模型验证的模型(测试数据集)。模型使用了不同的水质变量,包括T,pH,EC,HCO3-,F-,Cl-,SO42-,Na +,K +,Mg2 +和Ca2 +。在第一阶段,已基于相关系数构造了不同的输入组合,因此为建模阶段选择了最佳组合。不同的定量标准以及视觉比较方法已用于评估建模能力。结果表明,为了获得可靠的结果,还应将具有低相关性的变量与显示高相关系数的那些变量一起考虑为模型的输入。根据模型评估标准,GP算法在预测硝酸盐和锶的浓度,其次分别为RF,M5P和RT时,优于所有其他模型。结果还表明,模型的结构以及数据的准确性和结构可能会对模型的结果产生相关影响。










































 京公网安备 11010802027423号
京公网安备 11010802027423号