Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Blind method for discovering number of clusters in multidimensional datasets by regression on linkage hierarchies generated from random data.
PLOS ONE ( IF 2.9 ) Pub Date : 2020-01-23 , DOI: 10.1371/journal.pone.0227788 Osbert C Zalay 1
PLOS ONE ( IF 2.9 ) Pub Date : 2020-01-23 , DOI: 10.1371/journal.pone.0227788 Osbert C Zalay 1
Affiliation
|
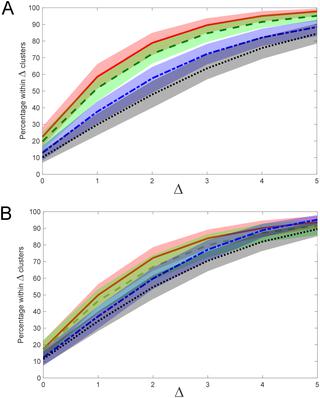
Determining intrinsic number of clusters in a multidimensional dataset is a commonly encountered problem in exploratory data analysis. Unsupervised clustering algorithms often rely on specification of cluster number as an input parameter. However, this is typically not known a priori. Many methods have been proposed to estimate cluster number, including statistical and information-theoretic approaches such as the gap statistic, but these methods are not always reliable when applied to non-normally distributed datasets containing outliers or noise. In this study, I propose a novel method called hierarchical linkage regression, which uses regression to estimate the intrinsic number of clusters in a multidimensional dataset. The method operates on the hypothesis that the organization of data into clusters can be inferred from the hierarchy generated by partitioning the dataset, and therefore does not directly depend on the specific values of the data or their distribution, but on their relative ranking within the partitioned set. Moreover, the technique does not require empirical data to train on, but can use synthetic data generated from random distributions to fit regression coefficients. The trained hierarchical linkage regression model is able to infer cluster number in test datasets of varying complexity and differing distributions, for image, text and numeric data, using the same regression model without retraining. The method performs favourably against other cluster number estimation techniques, and is also robust to parameter changes, as demonstrated by sensitivity analysis. The apparent robustness and generalizability of hierarchical linkage regression make it a promising tool for unsupervised exploratory data analysis and discovery.
中文翻译:

通过对随机数据生成的链接层次结构进行回归来发现多维数据集中的簇数的盲法。
确定多维数据集中聚类的固有数目是探索性数据分析中经常遇到的问题。无监督聚类算法通常依赖于聚类号的指定作为输入参数。然而,这通常不是先验的。已经提出了许多方法来估计聚类数,包括统计和信息理论方法,例如缺口统计,但是当这些方法应用于包含异常值或噪声的非正态分布数据集时,这些方法并不总是可靠的。在这项研究中,我提出了一种称为层次链接回归的新方法,该方法使用回归来估计多维数据集中聚类的固有数量。该方法基于以下假设:可以根据通过对数据集进行分区而生成的层次结构来推断将数据组织为簇的方式,因此该方法不直接取决于数据的特定值或其分布,而是取决于它们在分区内的相对排名组。此外,该技术不需要训练经验数据,但可以使用从随机分布生成的合成数据来拟合回归系数。经过训练的分层链接回归模型能够使用相同的回归模型来推断图像,文本和数字数据的复杂性和分布不同的测试数据集中的簇数,而无需重新训练。该方法的效果优于其他聚类数估算技术,并且对于参数更改也很健壮,如敏感性分析所示。层次链接回归的明显鲁棒性和可推广性使其成为无监督探索性数据分析和发现的有前途的工具。
更新日期:2020-01-24
中文翻译:
通过对随机数据生成的链接层次结构进行回归来发现多维数据集中的簇数的盲法。
确定多维数据集中聚类的固有数目是探索性数据分析中经常遇到的问题。无监督聚类算法通常依赖于聚类号的指定作为输入参数。然而,这通常不是先验的。已经提出了许多方法来估计聚类数,包括统计和信息理论方法,例如缺口统计,但是当这些方法应用于包含异常值或噪声的非正态分布数据集时,这些方法并不总是可靠的。在这项研究中,我提出了一种称为层次链接回归的新方法,该方法使用回归来估计多维数据集中聚类的固有数量。该方法基于以下假设:可以根据通过对数据集进行分区而生成的层次结构来推断将数据组织为簇的方式,因此该方法不直接取决于数据的特定值或其分布,而是取决于它们在分区内的相对排名组。此外,该技术不需要训练经验数据,但可以使用从随机分布生成的合成数据来拟合回归系数。经过训练的分层链接回归模型能够使用相同的回归模型来推断图像,文本和数字数据的复杂性和分布不同的测试数据集中的簇数,而无需重新训练。该方法的效果优于其他聚类数估算技术,并且对于参数更改也很健壮,如敏感性分析所示。层次链接回归的明显鲁棒性和可推广性使其成为无监督探索性数据分析和发现的有前途的工具。










































 京公网安备 11010802027423号
京公网安备 11010802027423号