Nature Reviews Chemistry ( IF 38.1 ) Pub Date : 2020-01-17 , DOI: 10.1038/s41570-019-0159-2 Catrin Sohrabi 1 , Andrew Foster 2 , Ali Tavassoli 1, 2
|
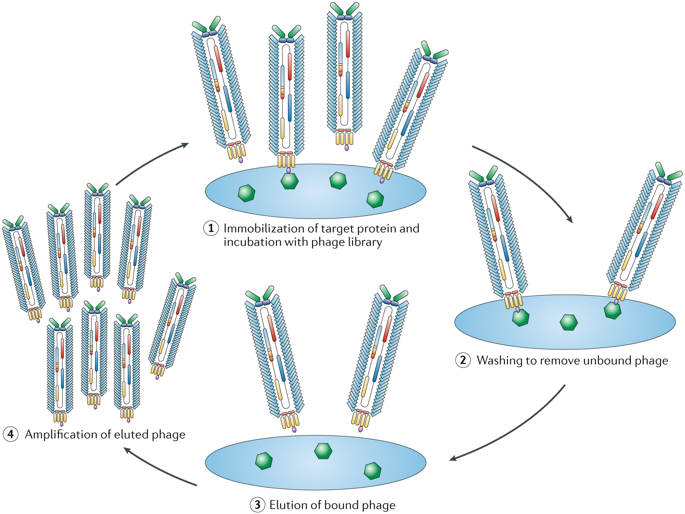
Drug discovery has traditionally focused on using libraries of small molecules to identify therapeutic drugs, but new modalities, especially libraries of genetically encoded cyclic peptides, are increasingly used for this purpose. Several technologies now exist for the production of libraries of cyclic peptides, including phage display, mRNA display and split-intein circular ligation of peptides and proteins. These different approaches are each compatible with particular methods of screening libraries, such as functional or affinity-based screening, and screening in vitro or in cells. These techniques allow the rapid preparation of libraries of hundreds of millions of molecules without the need for chemical synthesis, and have therefore lowered the entry barrier to generating and screening for inhibitors of a given target. This ease of use combined with the inherent advantages of the cyclic-peptide scaffold has yielded inhibitors of targets that have proved difficult to drug with small molecules. Multiple reports demonstrate that cyclic peptides act as privileged scaffolds in drug discovery, particularly against ‘undruggable’ targets such as protein–protein interactions. Although substantial challenges remain in the clinical translation of hits from screens of cyclic-peptide libraries, progress continues to be made in this area, with an increasing number of cyclic peptides entering clinical trials. Here, we detail the various platforms for producing and screening libraries of genetically encoded cyclic peptides and discuss and evaluate the advantages and disadvantages of each approach when deployed for drug discovery.
中文翻译:
在药物发现中生成和筛选基因编码环肽文库的方法
传统上,药物发现的重点是使用小分子库来识别治疗药物,但新的模式,尤其是基因编码的环肽库,越来越多地用于此目的。现在有几种技术可用于生产环肽文库,包括噬菌体展示、mRNA 展示以及肽和蛋白质的分裂内含子环状连接。这些不同的方法都与筛选文库的特定方法兼容,例如基于功能或亲和力的筛选,以及体外或细胞内筛选。这些技术允许在不需要化学合成的情况下快速制备数亿个分子的文库,因此降低了生成和筛选给定靶标抑制剂的进入壁垒。这种易用性与环肽支架的固有优势相结合,已经产生了靶点抑制剂,这些靶点已被证明难以用小分子药物治疗。多项报告表明,环肽在药物发现中充当特殊支架,特别是针对“不可药性”靶标,例如蛋白质-蛋白质相互作用。尽管环肽文库筛选结果的临床转化仍存在重大挑战,但随着越来越多的环肽进入临床试验,这一领域仍在不断取得进展。在这里,我们详细介绍了用于生成和筛选基因编码环肽文库的各种平台,并讨论和评估了每种方法在用于药物发现时的优缺点。










































 京公网安备 11010802027423号
京公网安备 11010802027423号