当前位置:
X-MOL 学术
›
Anal. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Retention Index Prediction Using Quantitative Structure–Retention Relationships for Improving Structure Identification in Nontargeted Metabolomics
Analytical Chemistry ( IF 6.7 ) Pub Date : 2018-06-28 00:00:00 , DOI: 10.1021/acs.analchem.8b02084 Yabin Wen 1 , Ruth I. J. Amos 1 , Mohammad Talebi 1 , Roman Szucs 2 , John W. Dolan 3 , Christopher A. Pohl 4 , Paul R. Haddad 1
Analytical Chemistry ( IF 6.7 ) Pub Date : 2018-06-28 00:00:00 , DOI: 10.1021/acs.analchem.8b02084 Yabin Wen 1 , Ruth I. J. Amos 1 , Mohammad Talebi 1 , Roman Szucs 2 , John W. Dolan 3 , Christopher A. Pohl 4 , Paul R. Haddad 1
Affiliation
|
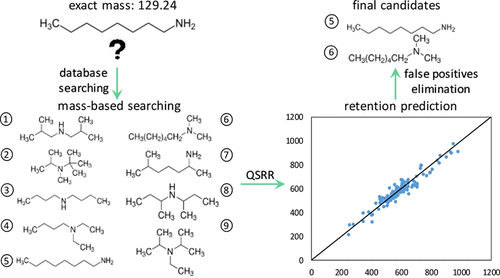
Structure identification in nontargeted metabolomics based on liquid-chromatography coupled to mass spectrometry (LC-MS) remains a significant challenge. Quantitative structure–retention relationship (QSRR) modeling is a technique capable of accelerating the structure identification of metabolites by predicting their retention, allowing false positives to be eliminated during the interpretation of metabolomics data. In this work, 191 compounds were grouped according to molecular weight and a QSRR study was carried out on the 34 resulting groups to eliminate false positives. Partial least squares (PLS) regression combined with a Genetic algorithm (GA) was applied to construct the linear QSRR models based on a variety of VolSurf+ molecular descriptors. A novel dual-filtering approach, which combines Tanimoto similarity (TS) searching as the primary filter and retention index (RI) similarity clustering as the secondary filter, was utilized to select compounds in training sets to derive the QSRR models yielding R2 of 0.8512 and an average root mean square error in prediction (RMSEP) of 8.45%. With a retention index filter expressed as ±2 standard deviations (SD) of the error, representative compounds were predicted with >91% accuracy, and for 53% of the groups (18/34), at least one false positive compound could be eliminated. The proposed strategy can thus narrow down the number of false positives to be assessed in nontargeted metabolomics.
中文翻译:

利用定量结构-保留关系预测保留指数,以改善非靶向代谢组学中的结构鉴定
基于液相色谱-质谱联用(LC-MS)的非靶向代谢组学中的结构鉴定仍然是一项重大挑战。定量结构-保留关系(QSRR)建模是一种能够通过预测代谢物的保留来加速代谢物的结构鉴定的技术,从而可以在解释代谢组学数据时消除假阳性。在这项工作中,根据分子量对191种化合物进行了分组,并对34个结果基团进行了QSRR研究,以消除假阳性。应用偏最小二乘(PLS)回归与遗传算法(GA)相结合,基于多种VolSurf +分子描述符构建了线性QSRR模型。一种新颖的双重过滤方法,R 2为0.8512,平均预测均方根误差(RMSEP)为8.45%。使用保留指数过滤器表示为误差的±2标准偏差(SD),可以预测具有91%以上准确度的代表性化合物,对于53%的组(18/34),可以消除至少一种假阳性化合物。因此,提出的策略可以缩小要在非靶向代谢组学中评估的假阳性的数量。
更新日期:2018-06-28
中文翻译:
利用定量结构-保留关系预测保留指数,以改善非靶向代谢组学中的结构鉴定
基于液相色谱-质谱联用(LC-MS)的非靶向代谢组学中的结构鉴定仍然是一项重大挑战。定量结构-保留关系(QSRR)建模是一种能够通过预测代谢物的保留来加速代谢物的结构鉴定的技术,从而可以在解释代谢组学数据时消除假阳性。在这项工作中,根据分子量对191种化合物进行了分组,并对34个结果基团进行了QSRR研究,以消除假阳性。应用偏最小二乘(PLS)回归与遗传算法(GA)相结合,基于多种VolSurf +分子描述符构建了线性QSRR模型。一种新颖的双重过滤方法,R 2为0.8512,平均预测均方根误差(RMSEP)为8.45%。使用保留指数过滤器表示为误差的±2标准偏差(SD),可以预测具有91%以上准确度的代表性化合物,对于53%的组(18/34),可以消除至少一种假阳性化合物。因此,提出的策略可以缩小要在非靶向代谢组学中评估的假阳性的数量。










































 京公网安备 11010802027423号
京公网安备 11010802027423号