当前位置:
X-MOL 学术
›
Chem. Bio. Drug Des.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Improving classical scoring functions using random forest: The non-additivity of free energy terms' contributions in binding.
Chemical Biology & Drug Design ( IF 3.2 ) Pub Date : 2018-04-27 , DOI: 10.1111/cbdd.13206 Karim Afifi 1 , Ahmed Farouk Al-Sadek 2
Chemical Biology & Drug Design ( IF 3.2 ) Pub Date : 2018-04-27 , DOI: 10.1111/cbdd.13206 Karim Afifi 1 , Ahmed Farouk Al-Sadek 2
Affiliation
|
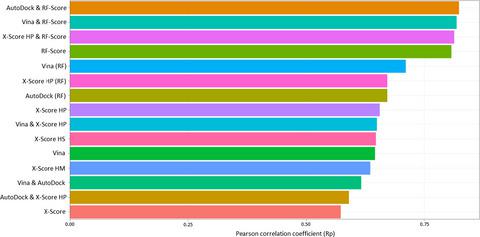
Despite recent efforts to improve the scoring performance of scoring functions, accurately predicting the binding affinity is still a challenging task. Therefore, different approaches were tried to improve the prediction performance of four scoring functions (x-score, vina, autodock, and rf-score) by substituting the linear regression model of classical scoring function by random forest to examine the performance improvement if an additive functional form is not imposed, and by combining different scoring functions into hybrid ones. The datasets were derived from the PDBbind-CN database version 2016. When evaluating the original scoring functions on the generic dataset, rf-score has outperformed classical scoring functions, which shows the superiority of descriptor-based scoring functions. Substituting linear regression as a linear model by random forest as a nonlinear model had largely improved the scoring performance of autodock and vina while x-score had only a slight performance increase. All hybrid scoring functions had only a slight improvement-if any-on both of the combined scoring functions, which is not worth the slower calculation time.
中文翻译:

使用随机森林改进经典评分功能:自由能项在绑定中的贡献不可加。
尽管最近为改善评分功能的评分性能做出了努力,但准确预测结合亲和力仍然是一项艰巨的任务。因此,尝试通过不同的方法来改善四个得分函数(x得分,vina,autodock和rf得分)的预测性能,方法是用随机森林替换经典得分函数的线性回归模型,以检查是否有添加剂,从而提高性能功能形式不是强制性的,而是通过将不同的评分功能组合到混合功能中来实现的。数据集来自PDBbind-CN数据库版本2016。在通用数据集上评估原始评分功能时,rf-score的性能优于经典评分功能,这显示了基于描述符的评分功能的优越性。用随机森林代替非线性模型将线性回归作为线性模型大大改善了自动停靠和比纳的得分表现,而x分数仅略有提高。所有混合计分功能仅在两个组合计分功能上有一点改进(如果有的话),这不值得花费较慢的计算时间。
更新日期:2018-04-27
中文翻译:
使用随机森林改进经典评分功能:自由能项在绑定中的贡献不可加。
尽管最近为改善评分功能的评分性能做出了努力,但准确预测结合亲和力仍然是一项艰巨的任务。因此,尝试通过不同的方法来改善四个得分函数(x得分,vina,autodock和rf得分)的预测性能,方法是用随机森林替换经典得分函数的线性回归模型,以检查是否有添加剂,从而提高性能功能形式不是强制性的,而是通过将不同的评分功能组合到混合功能中来实现的。数据集来自PDBbind-CN数据库版本2016。在通用数据集上评估原始评分功能时,rf-score的性能优于经典评分功能,这显示了基于描述符的评分功能的优越性。用随机森林代替非线性模型将线性回归作为线性模型大大改善了自动停靠和比纳的得分表现,而x分数仅略有提高。所有混合计分功能仅在两个组合计分功能上有一点改进(如果有的话),这不值得花费较慢的计算时间。










































 京公网安备 11010802027423号
京公网安备 11010802027423号