当前位置:
X-MOL 学术
›
J. Chem. Inf. Model.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Most Ligand-Based Classification Benchmarks Reward Memorization Rather than Generalization
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2018-04-26 00:00:00 , DOI: 10.1021/acs.jcim.7b00403 Izhar Wallach 1 , Abraham Heifets 1
Journal of Chemical Information and Modeling ( IF 5.6 ) Pub Date : 2018-04-26 00:00:00 , DOI: 10.1021/acs.jcim.7b00403 Izhar Wallach 1 , Abraham Heifets 1
Affiliation
|
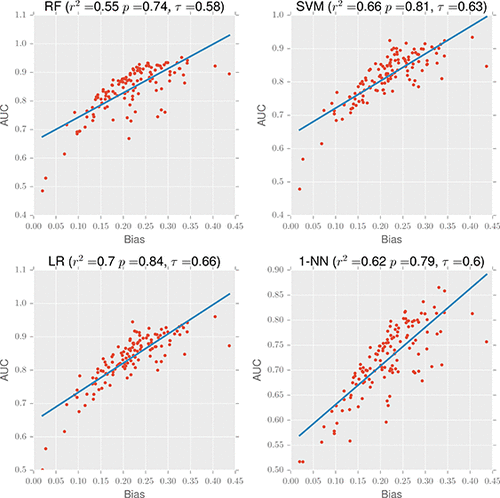
Undetected overfitting can occur when there are significant redundancies between training and validation data. We describe AVE, a new measure of training–validation redundancy for ligand-based classification problems, that accounts for the similarity among inactive molecules as well as active ones. We investigated seven widely used benchmarks for virtual screening and classification, and we show that the amount of AVE bias strongly correlates with the performance of ligand-based predictive methods irrespective of the predicted property, chemical fingerprint, similarity measure, or previously applied unbiasing techniques. Therefore, it may be the case that the previously reported performance of most ligand-based methods can be explained by overfitting to benchmarks rather than good prospective accuracy.
中文翻译:

大多数基于配体的分类基准奖励记忆而不是泛化
当训练和验证数据之间存在大量冗余时,可能会发生未检测到的过度拟合。我们描述了AVE,这是一种针对配体分类问题的训练验证冗余的新方法,它可以解释无活性分子与有活性分子之间的相似性。我们调查了七个广泛用于虚拟筛选和分类的基准,并且我们发现AVE偏倚的数量与基于配体的预测方法的性能密切相关,而与预测的特性,化学指纹,相似性度量或先前应用的无偏技术无关。因此,可能的情况是,先前报道的大多数基于配体的方法的性能可以通过过度拟合基准而不是良好的预期准确性来解释。
更新日期:2018-04-26
中文翻译:
大多数基于配体的分类基准奖励记忆而不是泛化
当训练和验证数据之间存在大量冗余时,可能会发生未检测到的过度拟合。我们描述了AVE,这是一种针对配体分类问题的训练验证冗余的新方法,它可以解释无活性分子与有活性分子之间的相似性。我们调查了七个广泛用于虚拟筛选和分类的基准,并且我们发现AVE偏倚的数量与基于配体的预测方法的性能密切相关,而与预测的特性,化学指纹,相似性度量或先前应用的无偏技术无关。因此,可能的情况是,先前报道的大多数基于配体的方法的性能可以通过过度拟合基准而不是良好的预期准确性来解释。










































 京公网安备 11010802027423号
京公网安备 11010802027423号