当前位置:
X-MOL 学术
›
Anal. Chim. Acta
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Hierarchical Cluster Analysis of Technical Replicates to Identify Interferents in Untargeted Mass Spectrometry Metabolomics
Analytica Chimica Acta ( IF 5.7 ) Pub Date : 2018-08-01 , DOI: 10.1016/j.aca.2018.03.013 Lindsay K. Caesar , Olav M. Kvalheim , Nadja B. Cech
Analytica Chimica Acta ( IF 5.7 ) Pub Date : 2018-08-01 , DOI: 10.1016/j.aca.2018.03.013 Lindsay K. Caesar , Olav M. Kvalheim , Nadja B. Cech
|
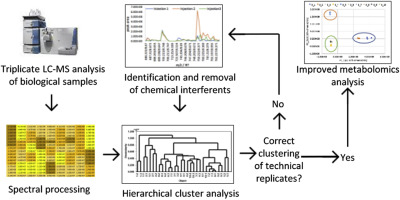
Mass spectral data sets often contain experimental artefacts, and data filtering prior to statistical analysis is crucial to extract reliable information. This is particularly true in untargeted metabolomics analyses, where the analyte(s) of interest are not known a priori. It is often assumed that chemical interferents (i.e. solvent contaminants such as plasticizers) are consistent across samples, and can be removed by background subtraction from blank injections. On the contrary, it is shown here that chemical contaminants may vary in abundance across each injection, potentially leading to their misidentification as relevant sample components. With this metabolomics study, we demonstrate the effectiveness of hierarchical cluster analysis (HCA) of replicate injections (technical replicates) as a methodology to identify chemical interferents and reduce their contaminating contribution to metabolomics models. Pools of metabolites with varying complexity were prepared from the botanical Angelica keiskei Koidzumi and spiked with known metabolites. Each set of pools was analyzed in triplicate and at multiple concentrations using ultraperformance liquid chromatography coupled to mass spectrometry (UPLC-MS). Before filtering, HCA failed to cluster replicates in the data sets. To identify contaminant peaks, we developed a filtering process that evaluated the relative peak area variance of each variable within triplicate injections. These interferent peaks were found across all samples, but did not show consistent peak area from injection to injection, even when evaluating the same chemical sample. This filtering process identified 128 ions that appear to originate from the UPLC-MS system. Data sets collected for a high number of pools with comparatively simple chemical composition were highly influenced by these chemical interferents, as were samples that were analyzed at a low concentration. When chemical interferent masses were removed, technical replicates clustered in all data sets. This work highlights the importance of technical replication in mass spectrometry-based studies, and presents a new application of HCA as a tool for evaluating the effectiveness of data filtering prior to statistical analysis.
中文翻译:

技术重复的分层聚类分析以识别非靶向质谱代谢组学中的干扰物
质谱数据集通常包含实验结果,统计分析之前的数据过滤对于提取可靠信息至关重要。这在非靶向代谢组学分析中尤其如此,其中感兴趣的分析物不是先验已知的。通常假设化学干扰物(即溶剂污染物,如增塑剂)在样品中是一致的,并且可以通过从空白进样中扣除背景来去除。相反,这里显示化学污染物在每次进样中的丰度可能不同,可能导致它们被误认为是相关的样品成分。通过这项代谢组学研究,我们证明了重复注射(技术重复)的层次聚类分析 (HCA) 作为一种方法来识别化学干扰物并减少其对代谢组学模型的污染贡献的有效性。具有不同复杂性的代谢物池是从植物当归 keiskei Koidzumi 中制备的,并加入已知代谢物。使用与质谱联用的超高效液相色谱法 (UPLC-MS) 以一式三份和多种浓度对每组集合进行分析。在过滤之前,HCA 未能对数据集中的副本进行聚类。为了识别污染物峰,我们开发了一种过滤过程,该过程评估了三次进样中每个变量的相对峰面积变化。在所有样品中都发现了这些干扰峰,但即使在评估相同的化学样品时,每次进样也没有显示一致的峰面积。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。与在低浓度下分析的样品一样。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。与在低浓度下分析的样品一样。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。
更新日期:2018-08-01
中文翻译:
技术重复的分层聚类分析以识别非靶向质谱代谢组学中的干扰物
质谱数据集通常包含实验结果,统计分析之前的数据过滤对于提取可靠信息至关重要。这在非靶向代谢组学分析中尤其如此,其中感兴趣的分析物不是先验已知的。通常假设化学干扰物(即溶剂污染物,如增塑剂)在样品中是一致的,并且可以通过从空白进样中扣除背景来去除。相反,这里显示化学污染物在每次进样中的丰度可能不同,可能导致它们被误认为是相关的样品成分。通过这项代谢组学研究,我们证明了重复注射(技术重复)的层次聚类分析 (HCA) 作为一种方法来识别化学干扰物并减少其对代谢组学模型的污染贡献的有效性。具有不同复杂性的代谢物池是从植物当归 keiskei Koidzumi 中制备的,并加入已知代谢物。使用与质谱联用的超高效液相色谱法 (UPLC-MS) 以一式三份和多种浓度对每组集合进行分析。在过滤之前,HCA 未能对数据集中的副本进行聚类。为了识别污染物峰,我们开发了一种过滤过程,该过程评估了三次进样中每个变量的相对峰面积变化。在所有样品中都发现了这些干扰峰,但即使在评估相同的化学样品时,每次进样也没有显示一致的峰面积。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。该过滤过程识别了 128 个似乎来自 UPLC-MS 系统的离子。为化学成分相对简单的大量池收集的数据集受这些化学干扰物的影响很大,在低浓度下分析的样品也是如此。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。与在低浓度下分析的样品一样。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。与在低浓度下分析的样品一样。去除化学干扰物质后,所有数据集中的技术重复都聚集在一起。这项工作强调了技术复制在基于质谱的研究中的重要性,并提出了 HCA 的新应用,作为在统计分析之前评估数据过滤有效性的工具。










































 京公网安备 11010802027423号
京公网安备 11010802027423号