当前位置:
X-MOL 学术
›
WIREs Comput. Mol. Sci.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
In silico toxicology: comprehensive benchmarking of multi‐label classification methods applied to chemical toxicity data
Wiley Interdisciplinary Reviews: Computational Molecular Science ( IF 11.4 ) Pub Date : 2017-12-04 , DOI: 10.1002/wcms.1352 Arwa B. Raies 1 , Vladimir B. Bajic 1
Wiley Interdisciplinary Reviews: Computational Molecular Science ( IF 11.4 ) Pub Date : 2017-12-04 , DOI: 10.1002/wcms.1352 Arwa B. Raies 1 , Vladimir B. Bajic 1
Affiliation
|
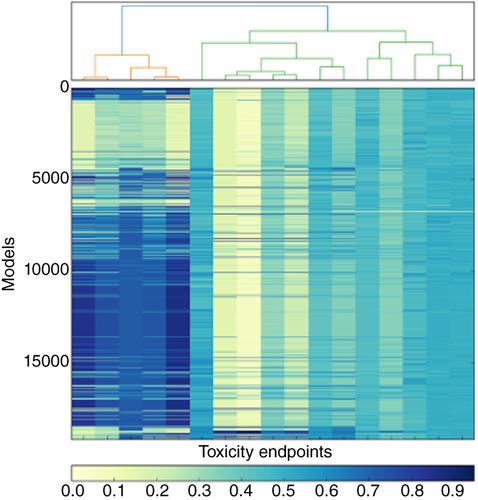
One goal of toxicity testing, among others, is identifying harmful effects of chemicals. Given the high demand for toxicity tests, it is necessary to conduct these tests for multiple toxicity endpoints for the same compound. Current computational toxicology methods aim at developing models mainly to predict a single toxicity endpoint. When chemicals cause several toxicity effects, one model is generated to predict toxicity for each endpoint, which can be labor and computationally intensive when the number of toxicity endpoints is large. Additionally, this approach does not take into consideration possible correlation between the endpoints. Therefore, there has been a recent shift in computational toxicity studies toward generating predictive models able to predict several toxicity endpoints by utilizing correlations between these endpoints. Applying such correlations jointly with compounds' features may improve model's performance and reduce the number of required models. This can be achieved through multi‐label classification methods. These methods have not undergone comprehensive benchmarking in the domain of predictive toxicology. Therefore, we performed extensive benchmarking and analysis of over 19,000 multi‐label classification models generated using combinations of the state‐of‐the‐art methods. The methods have been evaluated from different perspectives using various metrics to assess their effectiveness. We were able to illustrate variability in the performance of the methods under several conditions. This review will help researchers to select the most suitable method for the problem at hand and provide a baseline for evaluating new approaches. Based on this analysis, we provided recommendations for potential future directions in this area.
中文翻译:

计算机毒理学:适用于化学毒性数据的多标签分类方法的综合基准
毒性测试的一个目标尤其是确定化学物质的有害影响。鉴于对毒性测试的高要求,有必要对同一化合物的多个毒性终点进行这些测试。当前的计算毒理学方法旨在开发模型以主要预测单个毒性终点。当化学物质引起多种毒性作用时,将生成一个模型来预测每个端点的毒性,而当毒性端点的数量很大时,这可能是劳动和计算量很大的。此外,此方法未考虑端点之间可能的相关性。因此,在计算毒性研究中,最近发生了一种转变,即通过利用这些终点之间的相关性来生成能够预测多个毒性终点的预测模型。将此类相关性与化合物的特征一起应用可以提高模型的性能并减少所需模型的数量。这可以通过多标签分类方法来实现。这些方法尚未在预测毒理学领域进行全面的基准测试。因此,我们对使用最新方法组合生成的19,000多个多标签分类模型进行了广泛的基准测试和分析。已使用各种度量标准从不同角度评估了这些方法,以评估其有效性。我们能够说明在几种条件下方法性能的差异。这篇综述将帮助研究人员选择最适合当前问题的方法,并为评估新方法提供基准。
更新日期:2017-12-04
中文翻译:
计算机毒理学:适用于化学毒性数据的多标签分类方法的综合基准
毒性测试的一个目标尤其是确定化学物质的有害影响。鉴于对毒性测试的高要求,有必要对同一化合物的多个毒性终点进行这些测试。当前的计算毒理学方法旨在开发模型以主要预测单个毒性终点。当化学物质引起多种毒性作用时,将生成一个模型来预测每个端点的毒性,而当毒性端点的数量很大时,这可能是劳动和计算量很大的。此外,此方法未考虑端点之间可能的相关性。因此,在计算毒性研究中,最近发生了一种转变,即通过利用这些终点之间的相关性来生成能够预测多个毒性终点的预测模型。将此类相关性与化合物的特征一起应用可以提高模型的性能并减少所需模型的数量。这可以通过多标签分类方法来实现。这些方法尚未在预测毒理学领域进行全面的基准测试。因此,我们对使用最新方法组合生成的19,000多个多标签分类模型进行了广泛的基准测试和分析。已使用各种度量标准从不同角度评估了这些方法,以评估其有效性。我们能够说明在几种条件下方法性能的差异。这篇综述将帮助研究人员选择最适合当前问题的方法,并为评估新方法提供基准。


























 京公网安备 11010802027423号
京公网安备 11010802027423号