Scientific Reports ( IF 4.6 ) Pub Date : 2024-04-24 , DOI: 10.1038/s41598-024-58617-3 Julia A. Camilleri , Julia Volkening , Stefan Heim , Lisa N. Mochalski , Hannah Neufeld , Natalie Schlothauer , Gianna Kuhles , Simon B. Eickhoff , Susanne Weis
|
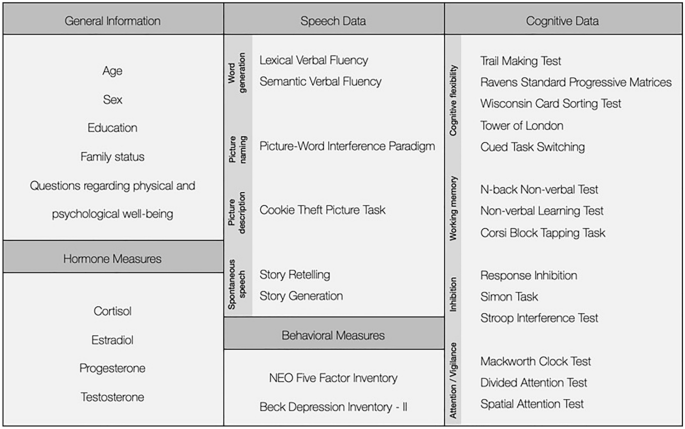
This work presents data from 148 German native speakers (20–55 years of age), who completed several speaking tasks, ranging from formal tests such as word production tests to more ecologically valid spontaneous tasks that were designed to mimic natural speech. This speech data is supplemented by performance measures on several standardised, computer-based executive functioning (EF) tests covering domains of working-memory, cognitive flexibility, inhibition, and attention. The speech and EF data are further complemented by a rich collection of demographic data that documents education level, family status, and physical and psychological well-being. Additionally, the dataset includes information of the participants’ hormone levels (cortisol, progesterone, oestradiol, and testosterone) at the time of testing. This dataset is thus a carefully curated, expansive collection of data that spans over different EF domains and includes both formal speaking tests as well as spontaneous speaking tasks, supplemented by valuable phenotypical information. This will thus provide the unique opportunity to perform a variety of analyses in the context of speech, EF, and inter-individual differences, and to our knowledge is the first of its kind in the German language. We refer to this dataset as SpEx since it combines speech and executive functioning data. Researchers interested in conducting exploratory or hypothesis-driven analyses in the field of individual differences in language and executive functioning, are encouraged to request access to this resource. Applicants will then be provided with an encrypted version of the data which can be downloaded.
中文翻译:
SpEx:言语和执行功能表现的德语数据集
这项工作提供了 148 名以德语为母语的人(20-55 岁)的数据,他们完成了多项口语任务,从词语生成测试等正式测试到旨在模仿自然语音的更生态有效的自发任务。这些语音数据还辅以多项标准化、基于计算机的执行功能 (EF) 测试的性能测量,涵盖工作记忆、认知灵活性、抑制和注意力等领域。丰富的人口统计数据进一步补充了语音和 EF 数据,这些数据记录了教育水平、家庭状况以及身心健康。此外,数据集还包括测试时参与者的激素水平(皮质醇、黄体酮、雌二醇和睾酮)信息。因此,该数据集是一个精心策划的、广泛的数据集合,涵盖不同的 EF 领域,包括正式口语测试和自发口语任务,并辅以有价值的表型信息。因此,这将为在语音、EF 和个体差异的背景下进行各种分析提供独特的机会,据我们所知,这在德语中尚属首次。我们将该数据集称为 SpEx,因为它结合了语音和执行功能数据。我们鼓励有兴趣在语言和执行功能的个体差异领域进行探索性或假设驱动分析的研究人员请求访问此资源。然后,申请人将获得可以下载的加密版本的数据。


























 京公网安备 11010802027423号
京公网安备 11010802027423号