Nature Chemical Biology ( IF 14.8 ) Pub Date : 2024-04-17 , DOI: 10.1038/s41589-024-01580-x Robert I. Horne , Ewa A. Andrzejewska , Parvez Alam , Z. Faidon Brotzakis , Ankit Srivastava , Alice Aubert , Magdalena Nowinska , Rebecca C. Gregory , Roxine Staats , Andrea Possenti , Sean Chia , Pietro Sormanni , Bernardino Ghetti , Byron Caughey , Tuomas P. J. Knowles , Michele Vendruscolo
|
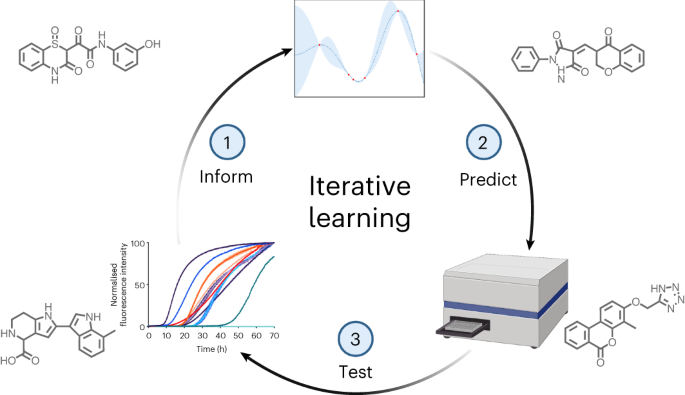
Machine learning methods hold the promise to reduce the costs and the failure rates of conventional drug discovery pipelines. This issue is especially pressing for neurodegenerative diseases, where the development of disease-modifying drugs has been particularly challenging. To address this problem, we describe here a machine learning approach to identify small molecule inhibitors of α-synuclein aggregation, a process implicated in Parkinson’s disease and other synucleinopathies. Because the proliferation of α-synuclein aggregates takes place through autocatalytic secondary nucleation, we aim to identify compounds that bind the catalytic sites on the surface of the aggregates. To achieve this goal, we use structure-based machine learning in an iterative manner to first identify and then progressively optimize secondary nucleation inhibitors. Our results demonstrate that this approach leads to the facile identification of compounds two orders of magnitude more potent than previously reported ones.
中文翻译:
使用基于结构的迭代学习发现 α-突触核蛋白聚集的有效抑制剂
机器学习方法有望降低传统药物发现流程的成本和失败率。对于神经退行性疾病来说,这个问题尤其紧迫,因为疾病缓解药物的开发尤其具有挑战性。为了解决这个问题,我们在这里描述了一种机器学习方法来识别 α-突触核蛋白聚集的小分子抑制剂,该过程与帕金森病和其他突触核蛋白病有关。由于 α-突触核蛋白聚集体的增殖是通过自催化二次成核发生的,因此我们的目标是识别与聚集体表面的催化位点结合的化合物。为了实现这一目标,我们以迭代方式使用基于结构的机器学习,首先识别并逐步优化二次成核抑制剂。我们的结果表明,这种方法可以轻松识别化合物,其效力比之前报道的化合物强两个数量级。





























 京公网安备 11010802027423号
京公网安备 11010802027423号