Scientific Data ( IF 9.8 ) Pub Date : 2024-04-11 , DOI: 10.1038/s41597-024-03171-w Tiffany J. Callahan , Ignacio J. Tripodi , Adrianne L. Stefanski , Luca Cappelletti , Sanya B. Taneja , Jordan M. Wyrwa , Elena Casiraghi , Nicolas A. Matentzoglu , Justin Reese , Jonathan C. Silverstein , Charles Tapley Hoyt , Richard D. Boyce , Scott A. Malec , Deepak R. Unni , Marcin P. Joachimiak , Peter N. Robinson , Christopher J. Mungall , Emanuele Cavalleri , Tommaso Fontana , Giorgio Valentini , Marco Mesiti , Lucas A. Gillenwater , Brook Santangelo , Nicole A. Vasilevsky , Robert Hoehndorf , Tellen D. Bennett , Patrick B. Ryan , George Hripcsak , Michael G. Kahn , Michael Bada , William A. Baumgartner , Lawrence E. Hunter
|
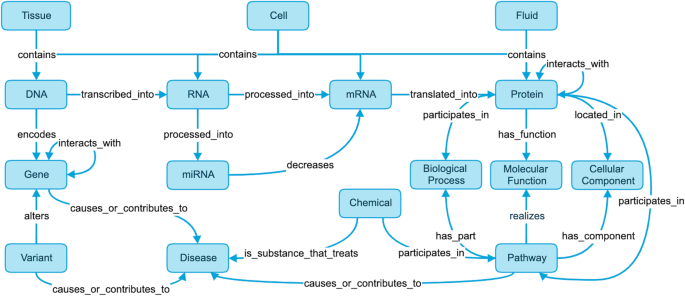
Translational research requires data at multiple scales of biological organization. Advancements in sequencing and multi-omics technologies have increased the availability of these data, but researchers face significant integration challenges. Knowledge graphs (KGs) are used to model complex phenomena, and methods exist to construct them automatically. However, tackling complex biomedical integration problems requires flexibility in the way knowledge is modeled. Moreover, existing KG construction methods provide robust tooling at the cost of fixed or limited choices among knowledge representation models. PheKnowLator (Phenotype Knowledge Translator) is a semantic ecosystem for automating the FAIR (Findable, Accessible, Interoperable, and Reusable) construction of ontologically grounded KGs with fully customizable knowledge representation. The ecosystem includes KG construction resources (e.g., data preparation APIs), analysis tools (e.g., SPARQL endpoint resources and abstraction algorithms), and benchmarks (e.g., prebuilt KGs). We evaluated the ecosystem by systematically comparing it to existing open-source KG construction methods and by analyzing its computational performance when used to construct 12 different large-scale KGs. With flexible knowledge representation, PheKnowLator enables fully customizable KGs without compromising performance or usability.
中文翻译:
生命科学的开源知识图生态系统
转化研究需要生物组织多个尺度的数据。测序和多组学技术的进步提高了这些数据的可用性,但研究人员面临着巨大的整合挑战。知识图(KG)用于对复杂现象进行建模,并且存在自动构建它们的方法。然而,解决复杂的生物医学集成问题需要知识建模方式的灵活性。此外,现有的知识图谱构建方法提供了强大的工具,但代价是知识表示模型的选择固定或有限。 PheKnowLator(表型知识翻译器)是一个语义生态系统,用于通过完全可定制的知识表示,自动构建基于本体的 KG 的 FAIR(可查找、可访问、可互操作和可重用)。该生态系统包括知识图谱构建资源(例如,数据准备API)、分析工具(例如,SPARQL端点资源和抽象算法)和基准(例如,预构建的知识图谱)。我们通过系统地将其与现有的开源知识图谱构建方法进行比较,并分析其用于构建 12 个不同的大规模知识图谱时的计算性能来评估该生态系统。通过灵活的知识表示,PheKnowLator 可以实现完全可定制的知识图谱,而不会影响性能或可用性。


























 京公网安备 11010802027423号
京公网安备 11010802027423号