Talanta ( IF 5.6 ) Pub Date : 2017-09-05 , DOI: 10.1016/j.talanta.2017.09.003 Dan Vrtiška , Pavel Šimáček
|
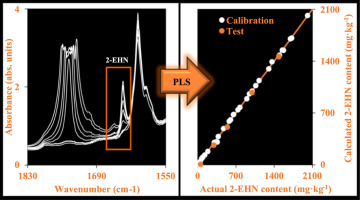
Quantification models based on the processing of FTIR spectra by partial least squares regression (PLS) were created in order to develop a method for the determination of 2-ethylhexyl nitrate (2-EHN) in diesel fuels. The set of standards was prepared using 2-EHN, biodiesel (FAME) and various mineral diesel fuels (2-EHN free). The standards were prepared in the concentration range of 2-EHN of 0–2436 mg kg−1. The set of the standards was divided into the calibration, validation and test sets. While the calibration set was used to build the model, validation set was used in order to optimize the model parameters. The test set of the standards was used to assess the predictive ability and repeatability of the model. Several hundreds of various models were developed and compared in order to find a suitable combination of the preprocessing methods and number of latent variables. The most promising model was developed using mean centered spectra in the form of their first derivative and smoothed using Gap-Segment derivative. The model showed quite good predictive ability and repeatability.
中文翻译:
使用FTIR和化学计量学预测柴油/生物柴油混合物中的2-EHN含量
建立了基于偏最小二乘回归(PLS)的FTIR光谱处理的定量模型,以开发一种测定柴油中硝酸2-乙基己酯(2-EHN)的方法。使用2-EHN,生物柴油(FAME)和各种矿物柴油燃料(不含2-EHN)准备了一套标准。在2-EHN浓度范围为0–2436 mg kg -1的条件下制备标准液。标准集分为校准集,验证集和测试集。使用校准集构建模型时,使用验证集来优化模型参数。使用标准测试集评估模型的预测能力和可重复性。为了找到预处理方法和潜在变量数量的合适组合,开发并比较了数百种各种模型。最有希望的模型是使用平均中心光谱以其一阶导数形式开发的,并使用Gap-Segment导数进行了平滑处理。该模型显示出相当好的预测能力和可重复性。










































 京公网安备 11010802027423号
京公网安备 11010802027423号