
Systematic Comparison of Objects Classification Methods Based on ALS and Optical Remote Sensing Images in Urban Areas

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
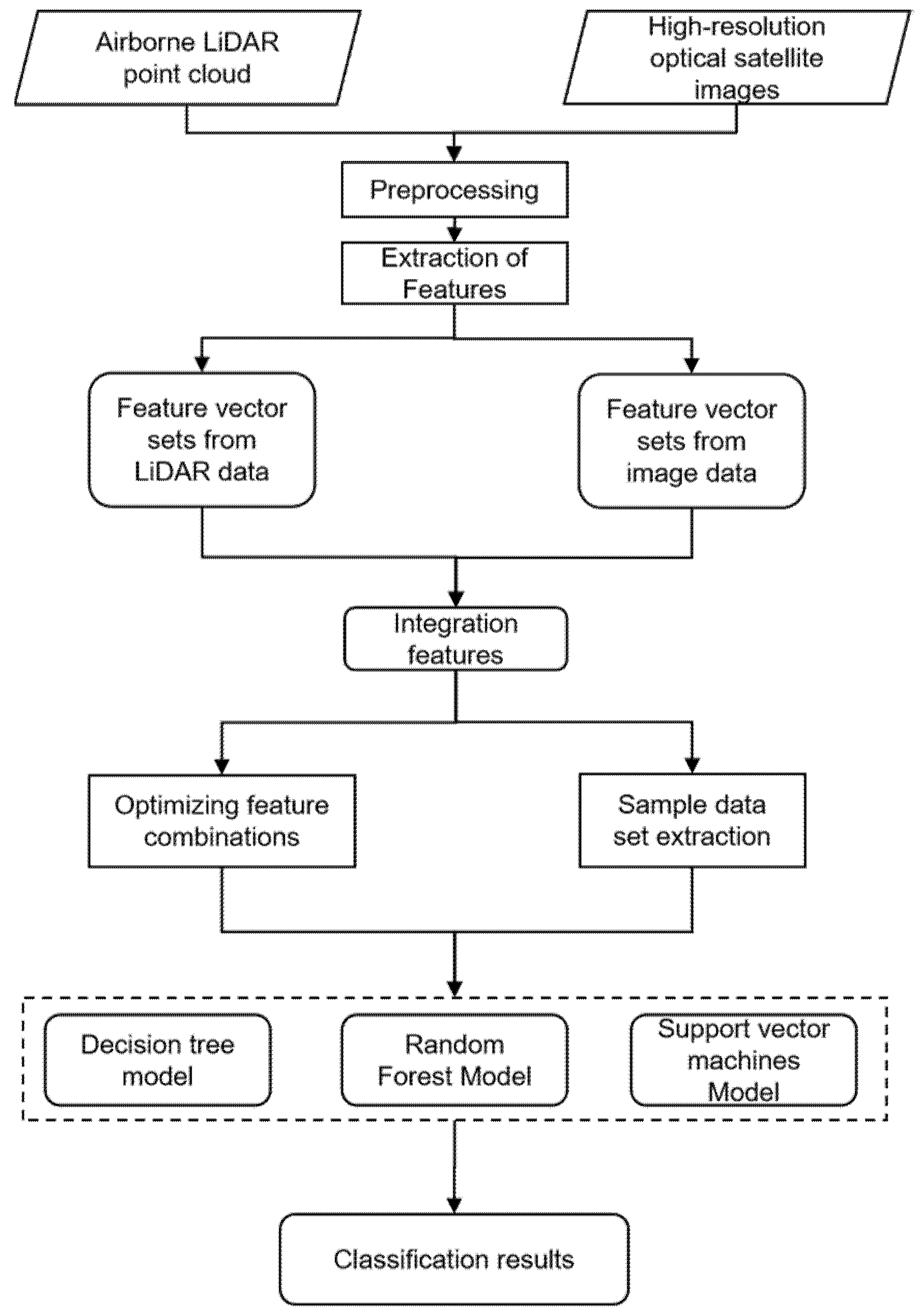
2.1. Technical Process
2.2. Feature Extraction and Fusion from Airborne LiDAR Point Clouds and Optical Images
2.3. Feature Sets Selection and Determination by PCA and Artificial Knowledge
2.4. Classifier Models of Object Classification in Urban Areas
3. Results
3.1. Experimental Data Sources
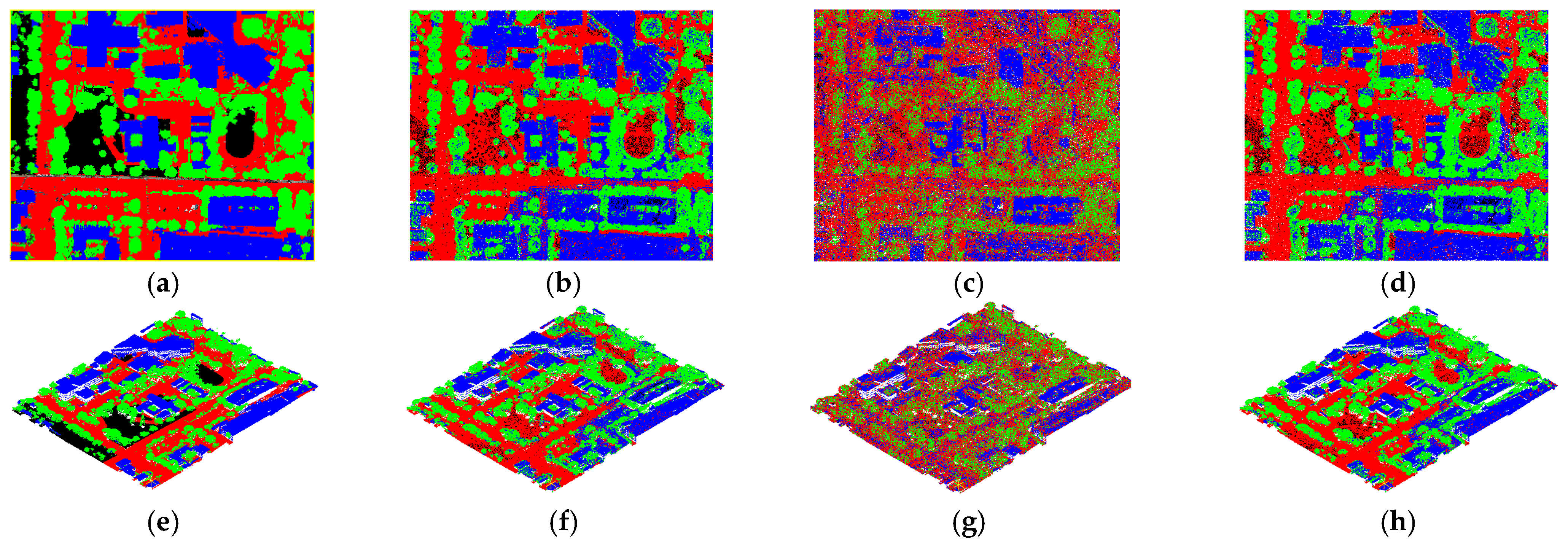
3.2. Comparisons between Different Data Sources
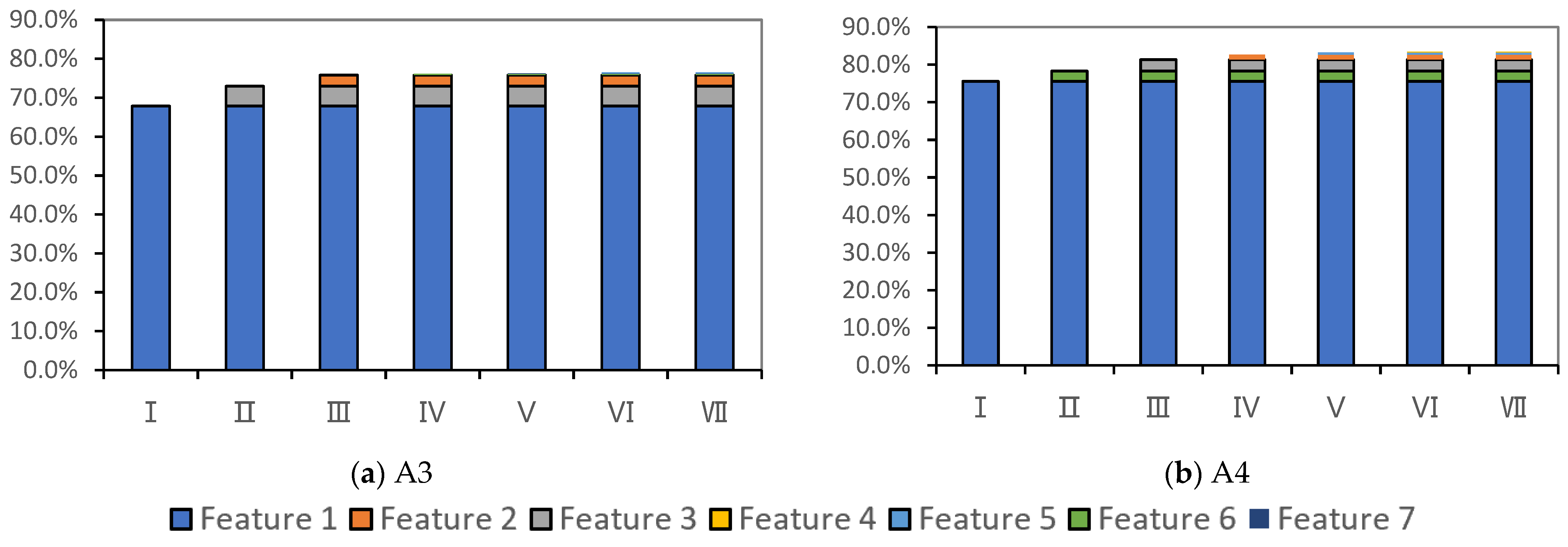
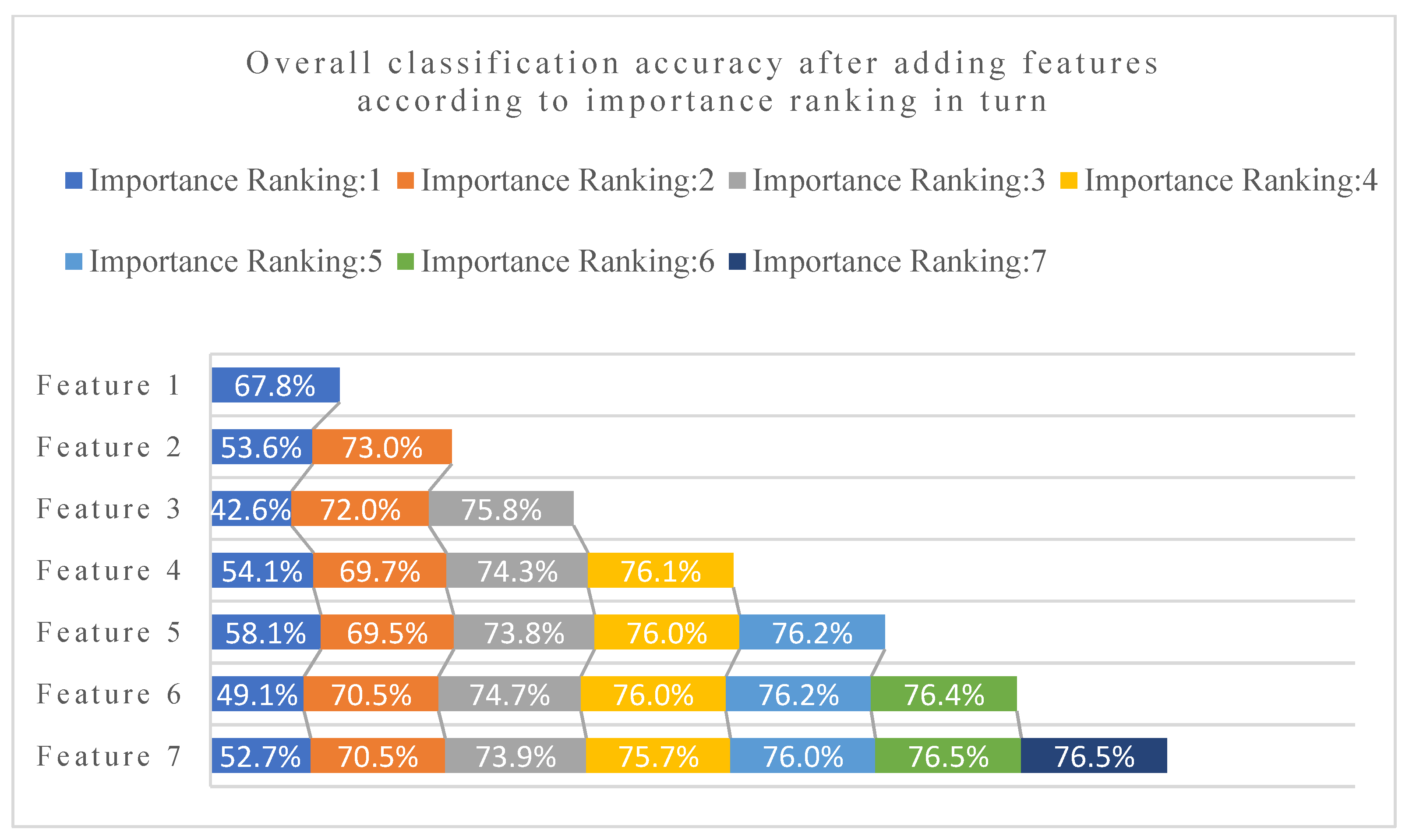
3.3. Combination and Optimization of Features
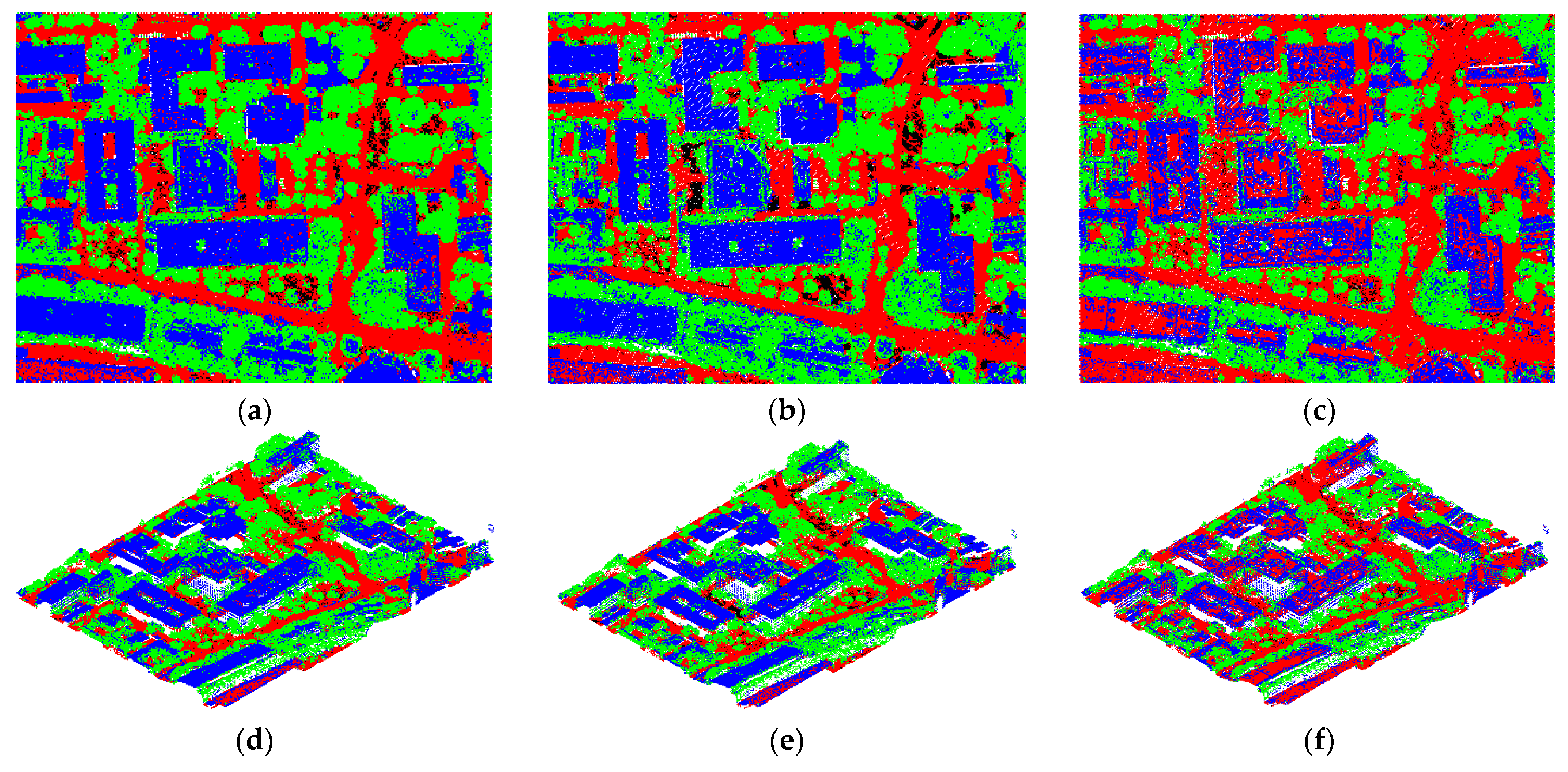
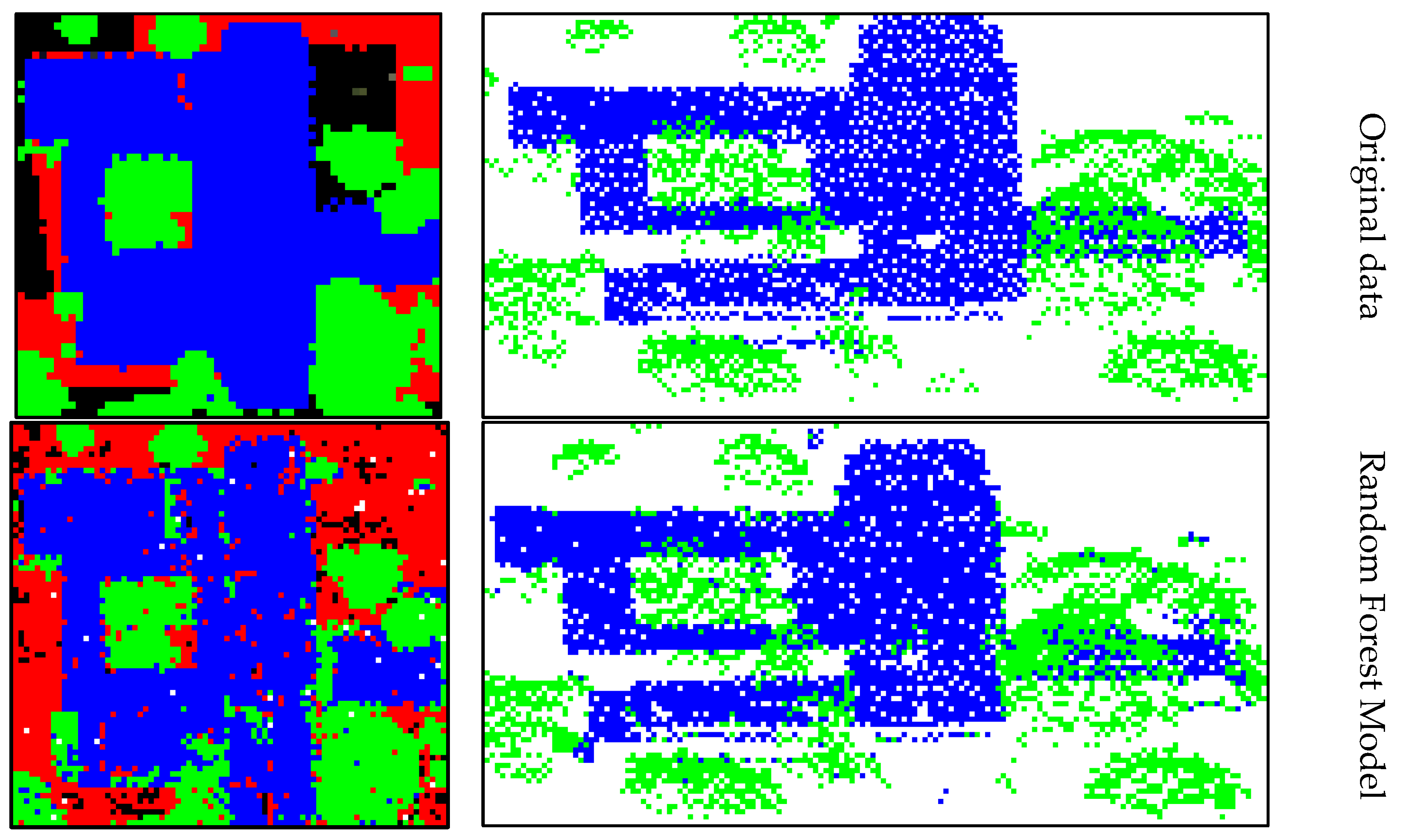
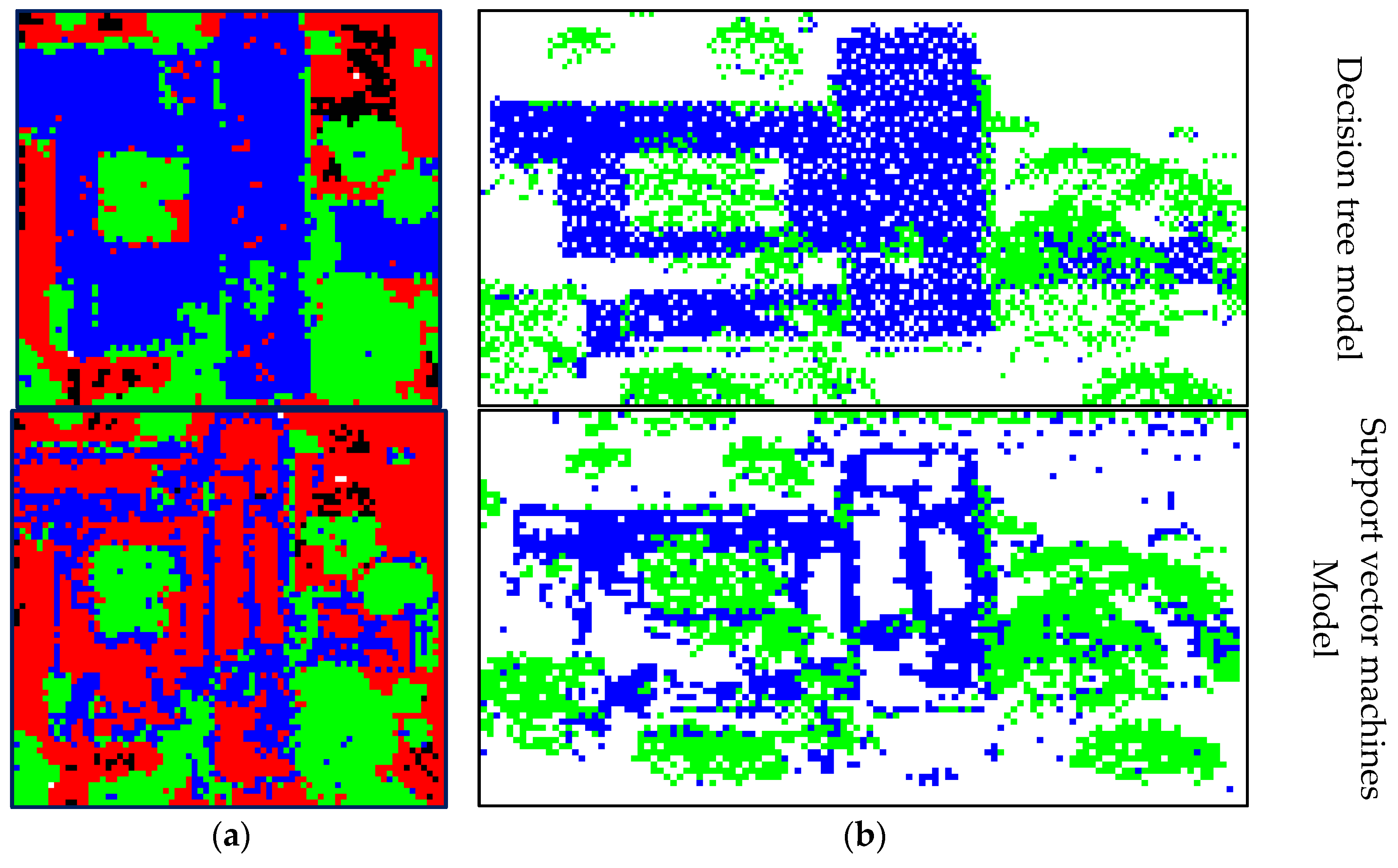
3.4. Effect of Different Classifiers on Classification Results
4. Discussion
4.1. Sensitivity Analysis of the Proportion of Sample Sets
4.2. Differences Analysis between Selected Feature Sets
4.3. AdaBoost (Adaptive Boosting) Classifier and Sample Imbalance Problem
4.4. Limitations of the Proposed Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dayo, Z.A.; Cao, Q.; Wang, Y.; Pirbhulal, S.; Sodhro, A.H. A Compact High-Gain Coplanar Waveguide-Fed Antenna for Military RADAR Applications. Int. J. Antennas Propag. 2020, 2020, 8024101. [Google Scholar] [CrossRef]
- Cheng, Z.; Ma, H. Automatic Extracting and Modeling Approach of City Cloverleaf from Airborne LiDAR Data. Acta Geod. Cartogr. Sin. 2012, 41, 7. [Google Scholar]
- Sampath, A.; Shan, J. Segmentation and Reconstruction of Polyhedral Building Roofs from Aerial Lidar Point Clouds. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1554–1567. [Google Scholar] [CrossRef]
- Sohn, G.; Huang, X.; Tao, V. Using a Binary Space Partitioning Tree for Reconstructing Polyhedral Building Models from Airborne Lidar Data. Photogramm. Eng. Remote Sens. 2008, 74, 1425–1440. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Z.; Li, A.; Liu, F. Large-scale urban point cloud labeling and reconstruction. ISPRS J. Photogramm. Remote Sens. 2018, 138, 86–100. [Google Scholar] [CrossRef]
- Tan, K.; Du, P. Hyperspectral remote sensing image classification based on support vector machine. J. Infrared Millim. Waves 2008, 27, 6. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Xiong, X. 3D Building Change Detection by Combining LiDAR Point Clouds and Aerial Imagery. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 7. [Google Scholar] [CrossRef]
- Mu, C.; Yu, J.; Xu, L.; Dun, P. Geomatics and Information Science of Wuhan University. Geomat. Inf. Sci. Wuhan Univ. 2009, 34, 414–417. [Google Scholar]
- Rebecca, L.P.; Dar, A.R.; Philip, E.D.; Laura, L.H. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens. Environ. 2007, 106, 253–267. [Google Scholar] [CrossRef]
- Paolo, G.; Fabio, D.A.; Belur, V.D. Urban remote sensing using multiple data sets: Past, present, and future. Inf. Fusion 2005, 6, 319–326. [Google Scholar] [CrossRef]
- Song, J.H.; Han, S.H.; Yu, K.; Kim, Y.I. Assessing the possibility of land-cover classification using lidar intensity data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 34, 259–262. [Google Scholar]
- Bellakaout, A.; Cherkaoui, M.; Ettarid, M.; Touzani, A. Automatic 3D Extraction of Buildings, Vegetation and Roads from LIDAR Data. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 173–180. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Kang, Z.; Wang, Z.; Kong, M. Airborne lidar point cloud classification fusion with dim point cloud. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 375–382. [Google Scholar] [CrossRef]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne lidar and multispectral image data for urban scene classification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Su, W.; Li, J.; Cheng, Y.; Zhang, J.; Hu, D.; Liu, C. Object-oriented Urban Land-cover Classification of Multi-scale Image Segmentation Method—A Case Study in Kuala Lumpur City Center, Malaysia. Natl. Remote Sens. Bull. 2007, 11, 521–530. [Google Scholar] [CrossRef]
- Cheng, X.; Cheng, X.; Hu, M.; Guo, W.; Zhang, L. Buildings Detection and Contour Extraction by Fusion of Aerial Images and LIDAR Point Cloud. Chin. J. Lasers 2016, 43, 9. [Google Scholar] [CrossRef]
- Suarez, J.; Ontiveros, C.; Smith, S.; Snape, S. Use of airborne LiDAR and aerial photography in the estimation of individual tree heights in forestry. Comput. Geosci. 2005, 31, 253–262. [Google Scholar] [CrossRef]
- Wang, X.; Li, P. Extraction of urban building damage using spectral, height and corner information from VHR satellite images and airborne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2020, 159, 322–336. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Automatic extraction of building roofs using LIDAR data and multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2013, 83, 1–18. [Google Scholar] [CrossRef]
- Parsian, S. Combining Hyperspectral and LiDAR Data for Building Extraction using Machine Learning Technique. Int. J. Comput. 2017, 2, 88–93. [Google Scholar]
- Qixia, M.; Pinliang, D.; Huadong, G. Pixel- and feature-level fusion of hyperspectral and lidar data for urban land-use classification. Int. J. Remote Sens. 2015, 36, 1618–1644. [Google Scholar] [CrossRef]
- Uezato, T.; Fauvel, M.; Dobigeon, N. Lidar-Driven Spatial Regularization for Hyperspectral Unmixing. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1740–1743. [Google Scholar]
- Wang, Y.; Chen, Q.; Liu, L.; Li, X.; Sangaiah, A.K.; Li, K. Systematic Comparison of Power Line Classification Methods from ALS and MLS Point Cloud Data. Remote Sens. 2018, 10, 1222. [Google Scholar] [CrossRef]
- Jingjing, C.; Kai, L.; Li, Z.; Lin, L.; Yuanhui, Z.; Liheng, P. Combining UAV-based hyperspectral and LiDAR data for mangrove species classification using the rotation forest algorithm. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102414. [Google Scholar] [CrossRef]
- Xiong, Y.; Gao, R.; Xu, Z. Random Forest Method for Dimension Reduction and Point Cloud Classification Based on Airborne LiDAR. Acta Geod. Cartogr. Sin. 2018, 47, 11. [Google Scholar] [CrossRef]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform lidar data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, S71–S84. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tong, X.; Bo, G.; Liang, Z.; Xing, X. Discriminative-Dictionary-Learning-Based Multilevel Point-Cluster Features for ALS Point-Cloud Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7309–7322. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Hu, X.; Xiu, L. Airborne LiDAR Point Cloud Classification in Urban Area Based on XGBoost and CRF. Remote Sens. Inf. 2020, 35, 5. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of Hyperspectral and LIDAR Remote Sensing Data for Classification of Complex Forest Areas. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1416–1427. [Google Scholar] [CrossRef]
- Du, N.; Peng, J. Decision-tree-based classification of airborne LiDAR point clouds. Sci. Surv. Mapp. 2013, 38, 118–120. [Google Scholar]
- Xu, F.; Zhang, X.; Shi, Y. Research on Classification of Land Cover based on LiDAR Cloud and Aerial Images. Remote Sens. Technol. Appl. 2019, 34, 10. [Google Scholar] [CrossRef]
- Dong, B. Research on Feature Classification Technology by Fusion of Airborne LiDAR Point Cloud and Remote Sensing Images; Information Engineering University: Zhengzhou, China, 2013. [Google Scholar]
- Mahmoudabadi, H.; Shoaf, T.; Olsen, M. Superpixel Clustering and Planar Fit Segmentation of 3D LIDAR Point Clouds. In Proceedings of the 2013 Fourth International Conference on Computing for Geospatial Research and Application, San Jose, CA, USA, 22–24 July 2013; pp. 1–7. [Google Scholar] [CrossRef]
- Hu, H.; Hui, Z.; Hui, Z. Airborne LiDAR Point Cloud Classification Based on Multiple-Entity Eigenvector Fusion. Chin. J. Lasers 2020, 47, 11. [Google Scholar]
- Ghamisi, P.; Benediktsson, J. Feature Selection Based on Hybridization of Genetic Algorithm and Particle Swarm Optimization. IEEE Geosci. Remote Sens. Lett. 2015, 12, 309–313. [Google Scholar] [CrossRef]
- Rasti, B.; Ghamisi, P.; Plaza, J.; Plaza, A. Fusion of Hyperspectral and LiDAR Data Using Sparse and Low-Rank Component Analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6354–6365. [Google Scholar] [CrossRef]
- Chehata, N.; Guo, L.; Mallet, C. Airborne LIDAR feature selection for urban classification using random forests. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, 38, 207–212. [Google Scholar]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Yan, G. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Zhang, K.; Qiao, S.; Kai, G. A new point cloud reconstruction algorithm based-on geometrical features. In Proceedings of the International Conference on Modelling, Identification and Control, Sousse, Tunisia, 18–20 December 2015. [Google Scholar]
- Breiman, L.; Breiman, L.; Cutler, R.A. Random Forests Machine Learning. J. Clin. Microbiol. 2001, 2, 199–228. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Calculation Methods | Descriptions |
|---|---|---|
| Normalized elevation values | Elevation values of features after eliminating the effect of slope | |
| Elevation Skewness | Measure of the direction and degree of skewness of the distribution of elevation statistics | |
| Elevation kurtosis | A measure of outliers in elevation statistics | |
| Absolute deviation of median elevation | Robust measures of sample variability in elevation statistics | |
| Absolute deviation of mean elevation | Median of the difference between the midpoint of elevation statistics and the mean of elevation | |
| Normalized Red-Green Difference Index | Indicators of vegetation and non-vegetation | |
| Echo intensity value | Echo intensity value | |
| The angle between the normal vector and the vertical direction | The angle between the normal vector and the vertical direction | |
| Coefficient of variation of texture features | M is the average DN value of the moving window | |
| Texture feature angle second order moment | Describes the uniformity of image grayscale distribution and texture roughness | |
| Texture feature information entropy | Expresses the amount of information the image has | |
| Homogeneity of textural features | Intensity and amplitude of the continuous variation of the gray level of the image element and its neighbors |
| Precision | Recall | OA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Feature Sets | Is | Gr | Tr | Ho | Is | Gr | Tr | Ho | |
| F_1 | 76.7% | 76.3% | 80.7% | 70.7% | 77.2% | 10.3% | 92.3% | 87.0% | 76.2% |
| F_2 | 76.2% | 53.3% | 80.6% | 66.5% | 76.0% | 10.8% | 88.1% | 84.9% | 74.2% |
| F_3 | 48.7% | 24.3% | 42.7% | 49.6% | 55.2% | 3.6% | 47.4% | 50.1% | 46.9% |
| Random Forest | Decision Tree | Support Vector Machine | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | OA | Precision | Recall | OA | Precision | Recall | OA | ||
| A3 | Tr | 80.7% | 92.3% | 76.2% | 76.0% | 90.8% | 74.5% | 83.0% | 87.9% | 68.6% |
| Ho | 70.7% | 87.0% | 67.3% | 83.8% | 59.0% | 62.0% | ||||
| A4 | Tr | 82.9% | 91.1% | 83.3% | 79.3% | 90.1% | 80.8% | 85.6% | 83.3% | 74.6% |
| Ho | 79.7% | 83.1% | 76.8% | 80.6% | 72.0% | 60.2% | ||||
| Method | F_1 | F_3 | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | OA | Precision | Recall | OA | |
| DT | 47.90% | 8.50% | 50.40% | 81.70% | 40.50% | 83.30% |
| AdaBoost | 48.30% | 17.10% | 52.50% | 85.90% | 40.10% | 86.20% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, H.; Wang, Y.; Lin, Y.; Li, S.; Wang, M.; Teng, F. Systematic Comparison of Objects Classification Methods Based on ALS and Optical Remote Sensing Images in Urban Areas. Electronics 2022, 11, 3041. https://doi.org/10.3390/electronics11193041
Cai H, Wang Y, Lin Y, Li S, Wang M, Teng F. Systematic Comparison of Objects Classification Methods Based on ALS and Optical Remote Sensing Images in Urban Areas. Electronics. 2022; 11(19):3041. https://doi.org/10.3390/electronics11193041
Chicago/Turabian StyleCai, Hengfan, Yanjun Wang, Yunhao Lin, Shaochun Li, Mengjie Wang, and Fei Teng. 2022. "Systematic Comparison of Objects Classification Methods Based on ALS and Optical Remote Sensing Images in Urban Areas" Electronics 11, no. 19: 3041. https://doi.org/10.3390/electronics11193041