
Abstract
This article introduces an iterative restricted OK estimator in generalized linear models to address the dilemma of multicollinearity by imposing exact linear restrictions on the parameters. It is a versatile estimator, which contains maximum likelihood (ML), restricted ML, Liu, restricted Liu, ridge and restricted ridge estimators in generalized linear models. To figure out the performance of restricted OK estimator over its counterparts, various comparisons are given where the performance evaluation criterion is the scalar mean square error (SMSE). Thus, illustrations and simulation studies for Gamma and Poisson responses are conducted apart from theoretical comparisons to see the performance of the estimators in terms of estimated and predicted MSE. Besides, the optimization techniques are applied to find the values of tuning parameters by minimizing SMSE and by using genetic algorithm.





Similar content being viewed by others
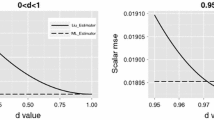

Notes
We call this estimator as the OK estimator, which denotes the first letters of authors name. By this way we make the difference between other two parameter estimators in the literature of linear regression.
When the response variable follows a normal distribution the working response equals to y and the weight matrix equals to the identity matrix
The sum of elements of \(\beta \) chosen in item 4 is zero
Bold text is used to show the minimum values corresponding to unrestricted estimators and bold italic text is used to show the minimum values correposnding to restricted estimators
Other (k, d) pairs are \((k_{AM},d)=(5.6870,0.8466)\) and \( (k_{GM},d)=(1.7808,0.8448)\)
The optimum (k, d) given in Sect. 4.1 is porposed when the restrictions are true. For that reason, we aim to use a restriction which is approximately true at leas for \({\hat{\beta }}_{ML}\)
Since \((k_{1},d_{1})\) and \((k_{2},d_{2})\) are same for Swedish football data, Table 2 is given for both \((k_{1},d_{1})\) and \((k_{2},d_{2})\)
Kurtoğlu and Özkale (2019b) used this data set as raw data with constant term.
When finding the VIF values from the centered and scaled \(X^{*T}X^{*} \), close to singular error exists which yields into negative VIF values in Matlab and not computation in R. Again, this is due to the problem of multicollinearity. Therefore, pinv (Moore-Penrose pseudoinverse) is used in calculating VIF values for ML estimator. For this reason, VIF values are smaller than 10.
Due to the previous note.
Other (k, d) computations are as \((k_{AM},d)=(7.3323,0.9987)\) and \( (k_{GM},d)=(0.3248,0.9732)\)
References
Abbasi A, Özkale MR (2021) The r-k class estimator in generalized linear models applicable with simulation and empirical study using a Poisson and Gamma responses. Hacet J Math Stat 50(2):594–611
Abdeslam A, El Bouanani F, Ben-Azza H (2014) Four parallel decoding schemas of product block codes. Trans Netw Commun 2:49–69
Amin M, Qasim M, Amanullah M (2019) Performance of Asar and Gen ç and Huang and Yang two-parameter estimation methods for the gamma regression model. Iran J Sci Technol Trans A Sci 43(6):2951–2963
Asar Y, Genç A (2017) Two-parameter ridge estimator in the binary logistic regression. Commun Stat Simul Comput 46(49):7088–7099
Asar Y, Genç A (2018) A new two-parameter estimator for the Poisson regression model. Iran J Sci Technol Trans Sci 42:793–803
Asar Y, Arashi M, Wu J (2017) Restricted ridge estimator in the logistic regression model. Commun Stat Simul Comput 46(8):6538–6544
Asar Y, Erişoğlu M, Arashi M (2017) Developing a restricted two-parameter Liu-type estimator: a comparison of restricted estimators in the binary logistic regression model. Commun Stat Theory Methods 46(14):6864–6873
Delaney NJ, Chatterjee S (1986) Use of the bootstrap and cross-validation in ridge regression. J Bus Econ Stat 4(2):255–62
Dorugade AV (2014) On comparison of some ridge parameters in Ridge Regression. Sri Lankan J Appl Stat 15(1)
Fallah R, Arashi M, Tabatabaey SMM (2017) On the ridge regression estimator with sub-space restriction. Commun Stat Theory Methods 46(23):11854–11865
Groß J (2003) Restricted ridge estimation. Stat Probab Lett 65:57–64
Hamed R, Hefnawy AE, Farag A (2013) Selection of the ridge parameter using mathematical programming. Commun Stat Simul Comput 42(6):1409–1432
Hoerl AE, Kennard RW, Baldwin KF (1975) Ridge regression: some simulations. Commun Stat 4:105–123
Holland J (1975) Adaptation in natural and artificial systems: an introductory analysis with application to biology, control and AI. The University of Michigan
Huang J, Yang H (2014) A two-parameter estimator in the negative binomial regression model. J Stat Comput Simul. 84(1):124–134
Iquebal MA, Prajneshu Ghosh H (2012) Genetic algorithm optimization technique for linear regression models with heteroscedastic errors. Indian J Agric Sci 82(5):422–426
Kibria BG (2003) Performance of some new ridge regression estimators. Commun Stat Simul Comput 32(2):419–435
Kurtoğlu F, Özkale MR (2016) Liu estimation in generalized linear models: application on Gamma distributed response variable. Stat Pap 57(4):911–928
Kurtoğlu F, Özkale MR (2019) Restricted ridge estimator in generalized linear models: Monte Carlo simulation studies on Poisson and binomial distributed responses. Commun Stat Simul Comput 48(4):1191–1218
Kurtoğlu F, Özkale MR (2019) Restricted Liu estimator in generalized linear models: Monte Carlo simulation studies on Gamma and Poisson distributed responses. Hacet J Math Stat 48(4):1250–1276
Lamari Y, Freskura B, Abdessamad A, Eichberg S, de Bonviller S (2020) Predicting spatial crime occurrences through an efficient ensemble-learning model. J Geoinf ISPRS Int https://doi.org/10.3390/ijgi9110645
Le Cessie S, Van Houwelingen JC (1992) Ridge estimators in logistic regression. J R Stat Soc 41(1):191–201
Lee AH, Silvapulle MJ (1988) Ridge estimation in logistic regression. Commun Stat Simul Comput 17(4):1231–1257
Li Y, Yang H (2010) A new stochastic mixed ridge estimator in linear regression model. Stat Pap 51(2):315–323
Mackinnon MJ, Puterman ML (1989) Collinearity in generalized linear models. Commun Stat Theory Methods 18(9):3463–3472
Månsson K, Shukur G (2011) A Poisson ridge regression estimator. Econ Model 28(4):1475–1481
Månsson K, Kibria BG, Shukur G (2012) On Liu estimators for the logit regression model. Econ Model 29(4):1483–1488
McDonald GC, Galarneau DI (1975) A Monte Carlo evaluation of ridge-type estimators. J Am Stat Assoc 70:407–416
Ndabashinze B, Şiray GU (2020) Comparing ordinary ridge and generalized ridge regression results obtained using genetic algorithms for ridge parameter selection. Commun Stat Simul Comput 31:1
Nelder JA, Wedderburn RWM (1972) Generalized linear models. J R Stat Soc A135:370–384
Nyquist H (1991) Restricted estimation of generalized linear models. Appl Stat 40(1):133–141
Özkale MR (2014) The relative efficiency of the restricted estimators in linear regression models. J Appl Stat 41(5):998–1027
Özkale MR (2016) Iterative algorithms of biased estimation methods in binary logistic regression. Stat Pap 57(4):991–1016
Özkale MR (2021) The red indicator and corrected VIFs in generalized linear models. Commun Stat Simul Comput 50(12):4144–4170
Özkale MR, Altuner H (2021) Bootstrap selection of ridge regularization parameter: a comparative study via a simulation study. Commun Stat Simul Comput. https://doi.org/10.1080/03610918.2021.1948574
Özkale MR, Kaçıranlar S (2007) The restricted and unrestricted two-parameter estimators. Commun Stat Theory Methods 36(15):2707–2725
Özkale MR, Nyquist H (2021) The stochastic restricted ridge estimator in generalized linear models. Stat Pap 62:1421–1460
Praga-Alejo RJ, Torres-Trevio LM, Pia-Monarrez MR (2008) Optimal determination of k constant of ridge regression using a simple genetic algorithm. Electron Robot Autom Mech Conf 39-44
Qasim M, Kibria BM, Mansson K, Sjölander P (2020) A new Poisson Liu regression estimator: method and application. J Appl Stat 47(12):2258–2271
Schaefer RL, Roi LD, Wolfe RA (1984) A ridge logistic estimator. Commun Stat Theory Methods 13(1):99–113
Scrucca L (2013) GA: a package for genetic algorithms in R. J Stat Softw 53(4):1–37
Segerstedt B (1992) On ordinary ridge regression in generalized linear models. Commun Stat Theory Methods 21(8):2227–2246
Siriwardene NR, Perera BJC (2006) Selection of genetic algorithm operators for urban drainage model parameter optimization. Mathe Comput Model 44(5–6):415–429
Tekeli E, Kaçıranlar S, Özbay N (2019) Optimal determination of the parameters of some biased estimators using genetic algorithm. J Stat Comput Simul 89(18):3331–53
Theil H (1963) On the use of incomplete prior information in regression analysis. J Am Stat Assoc 58(302):401–414
Theil H, Golberger AS (1961) On pure and mixed statistical estimation in economics. Int Econ Rev 2(1):65–78
Toutenburg H (1982) Prior information in linear models. Wiley, Chichester
Varathan N, Wijekoon P (2015) Stochastic restricted maximum likelihood estimator in logistic regression model. Open J Stat 5(7):837–851
Varathan N, Wijekoon P (2016) Ridge estimator in logistic regression under stochastic linear restrictions. Br J Math Comput Sci 15(3):1–14
Varathan N, Wijekoon P (2018) Liu-Type logistic estimator under stochastic linear restrictions. Ceylon J Sci 47(1):21–34
Varathan N, Wijekoon P (2019) Logistic Liu Estimator under stochastic linear restrictions. Stat Pap 60(3):945–962
Weissfeld LA, Sereika SM (1991) A multicollinearity diagnostic for generalized linear models. Commun Stat Theory Methods 20(4):1183–1198
Zhong Z, Yang H (2007) Ridge estimation to the restricted linear model. Commun Stat Theory Methods 36(11):2099–2115
Zuo W, Li Y (2018) A new stochastic restricted Liu estimator for the logistic regression model. Open J Stat 8(1):25–37
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Differentiating \(l(\theta ,\beta ,k,d;y,r)\) with respect to \(\beta _{j}\) and using the chain rule, we get
where \(w_{ii}=var(y_{i})(g^{^{\prime }}(\mu _{i}))^{2}\), since \( var(y_{i})=a(\phi )b^{^{\prime \prime }}(\theta _{i})\). In matrix form Eq. (11) can be written as
where \(W=Diag(w_{ii}^{-1})\) and \(D=Diag(g^{^{\prime }}(\mu _{i}))\) and \( \varLambda =Diag(\lambda _{1},\cdots ,\lambda _{t})\).
Now taking derivative of Eq. (11) with respect to \(\beta _{k}\), we have
where \(\delta _{jk}=1\), if \(j=k\), and 0 otherwise.
Minus times the expected value of Eq. (12) gives us:
In matrix notation, we can write it as
By using the method of Fisher’s scoring, we have
Premultiplying both sides by \(Q(\beta ,d,k)\), we get
By substituting the values, we have
where m denotes the iteration step and \({\hat{W}}_{kd-R}^{(m)}\) is a weight matrix evaluated at \({\hat{\beta }}_{kd-R}^{(m)}\). Then we obtain
By using inverse formula, we have
Then Eq. (13) be converted to
By considering:
Eq. (14) becomes
On further simplification, we get
Appendix B
Rights and permissions
About this article

Cite this article
Özkale, M.R., Abbasi, A. Iterative restricted OK estimator in generalized linear models and the selection of tuning parameters via MSE and genetic algorithm. Stat Papers 63, 1979–2040 (2022). https://doi.org/10.1007/s00362-022-01304-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-022-01304-0